This article, which extensively reviews–and compares–the Tecsun PL-880, PL-660, the Sangean ATS-909X, and the Sony ICF-SW7600GR, originally appeared in the June 2014 issue of The Spectrum Monitor Magazine. Without a doubt, it’s my longest and most comprehensive review to date.

Summer: time for travel–and for portable shortwave DXing. As I mentioned in the March TSM issue, I love combining travel with shortwave radio listening. But what radio should I pack?
This time of year, on the SWLing Post, I receive an increase in the number of queries asking some variation of the following, “What is the best, full-featured, portable shortwave radio on the market?” Oftentime it’s an upcoming trip, or just some time off work, that prompts the question, but without a doubt, this is the most-often-asked question from my readers. Typically, the reader has several models in mind and is curious how they compare. And since a good portable radio costs between $100 – $230 US, it’s not an impulse purchase decision for most of us.
In this month’s column, I hope to answer this question as thoroughly as possible so you can make an informed purchase decision that’s right for you. All four radios I mention in this article are what I would call “flagship portables” (generally, these are the best portables from any particular manufacturer). These were recently featured in a highly-energized reader survey on the SWLing Post, and are as follows: the Tecsun PL-660, the Tecsun PL-880, the Sony ICF-SW7600GR, and the Sangean ATS-909X.

The price tags for these radios fluctuate, but all are generally available between $100-$230 US, and are actively in production right now.
Moreover, all these radios have a similar form factor: they are portable enough to be operated handheld, sport a direct-frequency entry keypad, a dedicated external antenna jack, and a generous backlit display. All of them also have SSB, and all but one have selectable sideband synchronous detection.
The competitors
With the exception of the Sangean ATS-909X–on loan from a friend for the purposes of this review–I have easily spent 40+ hours of listening time with each of these radios. I know their individual characteristics quite well and have used them in a variety of situations.
In case you’re not familiar with each of the contenders, a brief summary of each radio follows with an overview of the features that make it unique.
Sangean ATS-909X

If there was an award for the best-looking radio, I think the ATS-909X would win. The 909X designers put a great deal of thought behind the design and ergonomics of the 909X; for instance, there are two indentations on the back of the radio which allow it to fit nicely in your hands. The 909X sports an internal speaker that produces excellent audio fidelity with a crisp response and even some distinct bass notes, especially notable if listening to an FM station. Of all of the radios listed here, the 909X has the the best variable receiver gain, tone control, largest display, and is the only radio with RDS (Radio Data System).
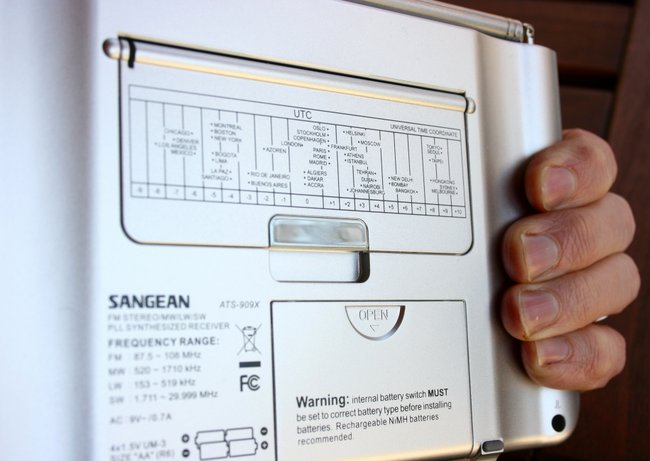
While I like the position of the tuning wheel on the front of the radio, which is ideal for tuning with your thumb and reminiscent of the ICF-SW55, I don’t like the indents you feel as you tune. If you’re a listener that takes advantage of radio memory, the ATS-909X has a very appealing feature: alpha-numeric memory tags. When you store a Radio Australia frequency to memory, your 909X can display the full station name in large, easy-to-read characters.

There is one omission from the 909X, though, that I find a bit surprising: it has no synchronous detection. While I don’t use a sync detector all of the time, it does come in handy when fading (QSB) and adjacent signal interference (if the sideband is selectable) are present. For a radio that costs over $210 US, on average–the priciest on this list, by a long shot–I feel like sync should have been a given.
Sony ICF-SW7600GR

The Sony ICF-SW7600GR comes from a series of “7600” portables that date back to 1977. Though the ’7600GR has all of the modern features one would expect for a radio in its price class, it’s a bare-bones receiver in this particular crowd. It lacks the advance memory functions of the PL-880, PL-660 and, especially, the 909X. The display is smaller and more basic, although it does provide the most vital information.
I have traveled extensively with the ’7600GR, however, as it has rock-solid, reliable performance; it’s my work horse and go-to radio for field recordings because I find its AGC and sync detector remain among the best in this class of radio. It also has a dedicated, stable line-out jack. Important controls are all accessible, and I can easily engage the key lock without fear of accidentally pressing the wrong button during the recording.

My main gripe about the ’7600GR, however, is its lack of a tuning knob and overall poor ergonomics. My personal preference is to use a tuning knob for band-scanning, as pressing buttons just doesn’t give the same sense of responsiveness. For casual tuning and band-scanning, I leave the ’7600GR in its case. Nor is this radio intuitive–indeed, to learn all but the most obvious functions of the ’7600GR, you’ll need to reference the owner’s manual. Audio from the ’7600’s internal speaker is average/unremarkable.
Still, my Sony ’7600GR’s solidity makes it a friend I would never part with. The real test? If it was ever lost or broken, I would promptly repair or replace this radio.
Tecsun PL-660

Though I’m often an early adopter of new shortwave portables, I wasn’t for the Tecsun PL-660. When it came out, I figured it would be redundant, considering the many other portables I own with synchronous detection.
Long story short: I was wrong.
Having at last acquired the Tecsun PL-660 last year, I now know it’s a pleasure to operate, and feature-rich for its price. The PL-660 is the bargain in this bunch of benchmark rigs, and significantly so: at an average price of $105 US currently, it is easily half the price of the ATS-909X.
The PL-660 is a pleasure to operate, and a true performer. Its selectable synchronous detector is one of the best in this group of portables: it’s on par with the Sony ICF-SW7600GR. It locks onto a station and rarely loses that lock. Ergonomics are excellent on the PL-660, too–the buttons have a tactile response, are well marked, and all functions are simple to find. The right side-mounted tuning knob has a smooth action.
The Tecsun PL-660 has been on the market since 2011 and has a dedicated following amongst SWLs, many of whom favor it above anything else in its class.
Of course, the PL-660 isn’t perfect, however. It lacks a line-out jack, something I find essential for recording shortwave broadcasts. The audio from the internal speaker is okay, but not on par with the ATS-909X, or its cousin, the PL-880 (below). Still, at $105 US, the PL-660 is truly a steal.
Tecsun PL-880

The Tecsun PL-880 only started shipping in November 2013. It was highly anticipated as the new flagship portable in the Tecsun line. The PL-880 is chock-full of features and without a doubt, is the most complicated portable I’ve ever reviewed.
The PL-880 feels like a quality piece of kit: its buttons have a highly-tactile response, the tuning/volume wheels are silky smooth, and feel well-engineered. Out of the four portables evaluated here, I find the PL-880 the most pleasurable to operate. One of my favorite features is its dedicated fine-tuning knob, just below the main tuning knob on the right side of the radio.

Unquestionably, the one feature which makes the PL-880 highly desirable is the amazing audio fidelity you’ll enjoy from its built-in speaker: it’s well-balanced, rich, and clear. I almost can’t emphasize this point enough–the PL-880’s speaker is capable of room-filling audio. It’s one of the few radios I’ve ever owned (other than some of my antique tube radios) that encourage listening to shortwave from across the room, with pleasing results.
The PL-880 also sports the most filter options of any other portable on the market. Indeed, in SSB mode, the filter can be narrowed all the way down to 500 hz, making this CW operator, at least, quite contented.
Cons? Yes, the PL-880 has some. First of all, I feel like its current firmware version leaves room for improvement. One of the first things I had to do after receiving my radio was adjust the muting threshold so that it wouldn’t engage. Many of the PL-880’s adjustments are mysteriously hidden, even undocumented in the manual. One such hidden feature is its synchronous detection, which is the least refined in this set of portables: it has difficulty maintaining a stable lock, thus audio is significantly compromised.
[Click here for our comprehensive (and growing) list of PL-880 hidden features.]
Changing settings often results in the radio “thinking” for a second or two, during which time it mutes the receiver. This phenomenon is most pronounced when changing modes (from AM to LSB, for example). I find it rather distracting.
Still, I do like the PL-880. Its audio and overall quality make up for any annoyances. I suspect it will have a long product life and a loyal following over the coming years.
Evaluating performance

Since I’m listening to the shortwaves 90% of the time I’m listening to a radio, I’ve limited the scope of my assessment here to the shortwave bands. With that said, none of these radios will disappoint you on AM or FM. I did note in my simple home comparison that the Sangean ATS-909X seemed to be the leader on the FM band. The Tecsuns were perhaps best on the AM (mediumwave) band.
But what about on shortwave? I like using recordings to evaluate shortwave radio performance, typically representative clips that are 25-60 seconds in length. Why? Anytime I have more than two radios to compare, it gets difficult to switch between radios, insuring that I give each one the same opportunity to receive a station. More importantly, with this method, I can listen to the audio clips on my computer, and flip between them quickly to determine characteristics I like in each.
Before recording, I set each radio in the same spot on a table, though I might change the orientation for optimal reception (since this can differ from one radio to another). I then extend the antennas fully and set all of the filters, gain controls, tone, volume levels, and frequencies to the same position on each rig. This way, my comparison can be on an “apples-to-apples” basis.
Note that I do not use an external antenna in any of these tests. This because I believe, when considering portables, they should be able to function very well off of their built-in antennas–thus taking into account situations in which employing an external antenna is not practical.
So that you have an opportunity to evaluate each radio in a “blind” test, I’ll tag each audio sample with a number, the order of which will not necessarily be consistent in each consecutive test. After the clips, I’ll reveal which is which.
Strong Signals

When I evaluate relatively strong broadcasts I typically listen for the best audio fidelity and signal stability a radio can offer. Unless there’s an adjacent signal (and in this case, there was not), I open the filter as widely as possible.
One of the strongest stations in my part of the world is Radio Havana Cuba–not always the cleanest signal, but always at blowtorch power levels. In this sample clip, I tuned our four radios to RHC.
To be fair, propagation from this station was poor the day of recording, so you’ll hear a little fading that is not normally present. Additionally, you’ll want to listen to the full clip, as a portion of each contains RHC interviews that were recorded by telephone (thus “tinnier” sounding); you’ll also hear the typical RHC transmitter hum:
Sample #1
Sample #2
Sample #3
Sample #4
You’ll hear that all of these receivers–with the exception of Sample #3–are nearly identical. Sample #3 is less sensitive than the others, thus more prone to shallow fading and a slightly higher noise level. To my ears, Sample #4 has the best audio quality and receiver characteristics, followed by Sample 2 and Sample 1.
Now let’s reveal the radios behind the samples:
- Sample #1: the Tecsun PL-660
- Sample #2: the Sony ICF-SW7600GR,
- Sample #3: the Sangean ATS-909X, and
- Sample #4: the Tecsun PL-880.
Weak signal DX

I like comparing radios while listening to weak signals and/or when conditions are less favorable. Since I often listen to weak signals (after all, so few broadcasts are actually directed to North America), it’s an important test.
I found a weak signal from Radio Romania International on 11,975 kHz. Normally, the signal would have been much stronger, but propagation was rough and QSB (fading) pronounced at times. Under these conditions, you get the opportunity to hear how the receiver’s AGC circuit handles fading and troughs, how the noise floor sounds as conditions change, and judge the overall sensitivity.
While I give priority to a receiver’s sensitivity and selectivity, there’s obviously more to evaluate here–for example, the more sensitive radio may be less pleasing to the ear.
If you like, jot down what you observe as you listen to each 50 second clip:
Sample #1
Sample #2
Sample #3
Sample #4
Obviously, the radio in Sample #4 is significantly less sensitive than the other radios–it truly struggled to hear the RRI signal under these conditions.
The other radios were able to hear RRI. Sample #3 sounded fine when there was no fading present, but in the fading troughs, there was a pronounced high-pitched noise–most likely a DSP-based noise. Sample #1 had pretty solid copy with stable AGC (automatic gain control). Sample #2 was the most sensitive of this bunch.
Now let’s reveal the radios behind the weak signal samples:
- Sample #1: the Sony ICF-SW7600GR,
- Sample #2: the Tecsun PL-660,
- Sample #3: the Tecsun PL-880, and
- Sample #4: the Sangean ATS-909X.
In this particular test, I was most impressed with the PL-660’s sensitivity, but given the choice, I would have chosen the Sony ICF-SW7600GR as the best overall. Why?
The Sony produced audio simply more pleasant to my ears due to the stability of the AGC.
Wondering if others would draw a similar conclusion, I posted the same clips above on my blog, the SWLing Post (http://wp.me/pn3uc-2pl). I doubted whether many readers would take the time to listen, or to vote, in this blind test. Boy, was I wrong–!
I received about seventy responses by email and in the comments section of my post. All but a very few readers ranked the clips in order of preference. The Sony was the clear favorite, with a total of 40 votes as the best of the bunch. The Tecsun PL-660 was second, with a total of 23 votes as the best. No one voted the PL-880 as best. (Click here for full results: http://wp.me/pn3uc-2qH)
What became very clear from the results and the comments, however, was that people who prefer sensitivity, prefered the PL-660. People who preferred stability, preferred the ’7600GR. In a sense, both were “best,” simply depending on the listener’s preference and/or listening requirements.
Weak single-sideband (SSB)

To test the SSB performance of these radios, I tuned to W1AW as they worked a pile-up from Puerto Rico. You will hear some fading. For those of you not familiar with SSB listening, you should note that W1AW sounds a little “grainy” in all of these recordings; this is simply the audio processor on W1AW’s transceiver which is set to be most audible and punch through the static.
Sample #1
Sample #2
Sample #3
Sample #4
W1AW is barely audible in Sample #1. In Sample #2, audio is well-balanced, with good audio, low noise, and a stable AGC. Sample #3 sounds more narrow (even though its filter, like all, was set to the widest setting), but the audio “pops out” of the static and is very intelligible. Sample #4 sounds much like Sample #2, perhaps slightly more sensitive but with slightly less stable AGC.
By now you may have guessed each radio behind these samples…Here’s the lowdown:
- Sample #1: the Sangean ATS-909X,
- Sample #2: the Sony ICF-SW7600GR,
- Sample #3: the Tecsun PL-880, and
- Sample #4: the Tecsun PL-660.
I believe the Tecsuns perform best in this category, even though the difference between the two models is pretty dramatic. The PL-880 has the best sensitivity in SSB–indeed, I could have probably lowered the gain on my recorder and made the background noise sound even less pronounced, but I wanted the levels to match the other receivers. I was somewhat surprised its 5 kHz filter sounded so narrow on SSB.
The Tecsun PL-660 had the most pleasant audio, but during QSB peaks, its audio would suffer a little distortion (you only hear this once in this sample, near the end of the recording). The Sony had slightly less sensitivity, but the most stable AGC.
Once again, the Sangean ATS-909X struggled to hear the signal, having the least sensitivity of the group.
A note about the Sangean ATS-909X

Alas, the most disappointing radio in all of these tests is the Sangean ATS-909X.
To be fair, however, it’s worth noting that the Sangean performs admirably if connected to an external antenna. Again, I resisted connecting an external antenna in this particular series of tests because I believe a good portable radio’s performance should first be judged upon what it can receive with only its telescoping whip antenna, considering that, when traveling, it’s not always possible to use an external antenna.
Indeed, if you plan to buy a portable that will be hooked up to an external antenna more often than not, the Sangean ATS-909X may be a good choice for you. Its front end can handle external antennas better than most of the radios above (with the Sony as an exception, in my experience).
Syncronous detection
I did not test sync detection, as the Sangean ATS-909X lacks a sync detector and the Tecsun PL-880’s sync detector leaves much to be desired. But many hours of listening to the Sony ’7600GR and the Tecsun PL-660 leads me to conclude that their sync detectors are fairly comparable in performance.
So, how do you translate these results?
Although all of these receivers are considered best in the portable realm for a particular manufacturer, each has a character that suits individual listening skills or requirements.
Herein lies the difficulty offering advice on which portable to purchase. Because radio listening tends to be a solitary hobby, it comes down to personal preference–like choosing a friend. What one person values may matter very little to someone else.
For example, I rarely (if ever) save stations to memory on a permanent basis. Other than temporary auto-tuning memory features, I never give memory functions any weight when making a purchase decision (for myself, that is). Yet there are listeners who place a great deal of emphasis on memory functions.
To be perfectly honest, I think each one of these radios has an individual character that makes it a stand out for a particular type of listening. While I often sort through my collection to give away radios that I seldom use, you won’t find me letting go of any of these rigs. The Sony ICF-SW7600GR is still my favorite portable for field recordings; its stable nature and robust front end mean that I can hook up long wire antennas if I wish. The PL-880 is the radio I reach for if want robust sound and armchair listening to shortwave and mediumwave–I also find it the best of the bunch to tune, a quality machine harkening back to the glory days of Panasonic and Sony. The PL-660 is my simple, bullet-proof performer–when in doubt of conditions, it’s the radio I reach for. If I owned the Sangean ATS-909X, it would probably become my bedside shortwave; its audio fidelity, large display, stable back stand, and ability to benefit from an external antenna make it very appealing for this purpose.
You can’t go wrong with any of these benchmark performers, so long as you know its weaknesses and strengths–which I hope this review has made clear.
If I had to choose just one of these radios…

I’m forcing myself answer this question. While it’s difficult to answer, I believe if I could only have one of these radios for travel…I would chose the Tecsun PL-660. I find it the best overall performer, and a true bargain at its price point.
To be clear, if the Sony ICF-SW7600GR only had a tuning knob, it would be my choice, instead. If the Tecsun PL-880 handled weak broadcast signals better, it might be my choice.
But this is my personal choice; you might have a completely different answer. I guess that’s the point I made earlier–it all depends on the listener.
Now…which do you choose?
Very nice – excellent comparison of these radios.
Very surprisingly, Sony has 5 flaws I found (and fixed) on ICF-SW7600GR:
1) on FM, the capacitor from the RF stage output coil to the CXA IC is 10nF(!) instead of 5…10pF. Funny enough, with 10pF the coil increases RF voltage and selectivituy of the RF stage as well as intermods are going away. Plus, the input RF coil has a place on the PCB on its primary side for – blocking capacitor (10nF) which is not there but should be (cancelling PCB grounding design issues). FM filters should be 110kHz “low loss” instead of of 300kHz (or more) originally installed. The RF stage should be realigned on 107.50MHz capacitors only. Antenna coupling capacitor for FM should be 220pf instead of 10nF.
2) Output capacitors (speaker, headphones) should be 330uF (big sound improvement).
3) On AM, all of filters parallel to the input FET should be removed, gate resisor for this FET should be 1M and antenna coupling capacitor 10nF. The capacitor adjustment for 1st IF should be used to obtain fully symmetry on AM (on AM radio there should be no difference switching USB/LSB either on Sync or SSB mode, it is possible with a little patience).
This way ICF-SW7600GR becomes extremely sensitive and usable. I don’t know why is Sony selling it that crippled. That CXA IC is the far best on the market, FM stereo decoder is phantastic. Enjoy!
Ein ausgezeichneter und fundierter Test, den ich zumindest in Punkto Sony und dem 880 bestätigen kann.
Ich bin übrigens der selben Meinung : ein Reiseradio sollte am besten mit seiner eigenen Antenne arbeiten können – ich kann jedenfalls nicht jedes Mal meine Antennen mitschleppen. Wer lieber über Außenantennen empfangen möchte, ist hier meiner Meinung nach falsch – da sollte man sich einen Tisch- oder Profiempfänger zulegen. Reiseempfänger bzw. Taschenradios – sagt eigentlich der Name schon – müssen klein sein und sollen trotzdem gut sein im Empfang – bei mir tat es bisher der 7600GR, der Tecsun PL880 ist auf den Lang- und Mittelwellen mindestens gleichwertig zum Sony, aber auf Kurzwelle ist mein Modell (8820 Bj. 2022) deutlich besser, als der Sony.
Auf alle Fälle war die Rezension sehr lesenswehrt und informativ – recht vielen Dank dafür und weiter so !
Liebe Grüße aus Deutschland – Sachsen-Anhalt – Dessau
Ronald
This is one of the best reviews about radios I’ve ever read. That is why I keep coming back whenever someone ask me about any of these radios (some of them I have). I had the soft muting/auto-squelch filter of my PL-660 deactivated and it improved even further its performance overal on LW/MW/SW.
I have both a Tecsun PL660 and a Sony 7600GR.
I did like the Tecsun better but it died after about 3 months.
The Tecsun would some times not tune and then progressed to not starting when checked I found the small enclosed internal small internal power supply was not working.
I have had the Sony for 18 years and still works.
I did have the common production fault on the Sony where the reciever would not resolve SSB because it was all warbly this robbed me of use of SSB. For a ham radio operator this was very disappointing and I cannot for give Sony for this.
I have now fixed this after finding the remedy on the net, reversed the capacitor.
I sold my PL-880 and S-8800 because their performance is disgraceful on SSB and Tecsun should really be ashamed for releasing radios of such poor quality at such ah high price.
I got the PL-680 instead and the noisefloor is lower and the audio is much better and it works as expected on SSB, sounds wonderful, great analogue sound not mutilated by bad DSP.
I can zerobeat on LW/MW/SW, couldn’t do this on the 880 or 8800 because of the bad distorted sound on SSB and the sound had a warble I couldn’t get rid of.
If only the 680 external antenna worked on LW/MW.
I believe the PL-990 also suffers badly on SSB and SYNC detection, perhaps it’s time for Tecsun to forget about DSP altogether ? it might be good for marketing but performance is rubbish.
Is Tecsun’s DSP radio (ex: PL-380) better or worse than the PL-660 for MW?
The PL-660 is better for MW than the PL-380. I compared both and the PL-660 not only is more sensitive but also its AGC works much better qsb and fluttering and you can also use synch detect or ECSS (ssb for am mode broadcasting). which is a great feature for avoiding splatter and stabilizing audio. It also has an RF attenuator with three settings in case of a very powerful MW transmitter nearby.
I went ahead and bought a 660 instread of an 880 or 990.
Does anyone know the bandwifth values (in kHz) of the 660’s wide and narrow settings for SW and MW?
B.
Excellent review, thank you very much for taking the time and effort to do it.
Thank you also to everyone who has responded and shared their views on the various receivers.
My favourite portable is the Sony ICF 2010 / 2001D, for wideband it simply outperforms the others, it outperforms the Lowe 150 as well, I did a side-by-side test in a remote area in SE Asia of the Lowe and the 2010 / 2001D, the BBC World Service on 15mhz came in loud and clear on the Sony but was very faint and like a whisper on the Lowe
I’ve never tried the Eton E1, though I hear it is like a Drake SW8 but updated and the big news on that front is that Eton are re-releasing the E1 – currently scheduled according to Universal Radio’s website – for Q1 2020, that time frame may slip… for details of this seemingly excellent receiver check out the Universal Radios website – no I have no links whatever to Universal!
I own or have owned the two Tecsuns reviewed, the 660 and the 880. The 660 is a good receiver, I gave it to my brother as a Christmas present.
I’d like to try the Sanegan 909AX, but – you may laugh at this – its price in Hong Kong is at the top end of the Amazon prices and so far I’ve resisted buying one on-line.
The Tecsun 880 looks fantastic, I love the separate fine tuning knob. 10Hz tuning steps in a package that’s the same size as the Sony 7600! The Tecsun’s list of features, a great selection of filters from 9KHz to 0.5KHz looks excellent, but I find it does not match the Sony 2010 / 2001D – though I wish very much that it did.
I agree. I own a PL-660, which I mostly operate with a 100 ft long wire and find the combination remarkable. If I could ask for one thing, I wish I could choose filters and narrow the range a bit, but for the money, I couldn’t be happier. It’s an excellent radio.
Przeczytalem wszystkie recenzje U?ywam IC SONY 7600 D do odbioru SSB programem FLdigi W EUROPE HF-FAX 3855KHz \ RTTY 4855 KHz \ SSTV 14230KHz W radio IC SONY jest mankament + power jest na ground Chc?c odebra? out TAPE dla karty Sound zastosowa?em d?awik 1\2 z zasilacza TV CRT Antena zewn?trzna 10 metrów drutu, fider 50 Ohm pol?czony w 1\2 d?ugo?ci drutu Ciekaw jestem które radio wymienione w recenzji na forum jest dobre w opcji odbioru software Fldigi.com
My Pl-660 worked great- until it completely died. I found out too late that this very expensive, average quality radio has a history of self-destruction after a year or so…
I looked online for any help and was informed that “they just die after a while!” There goes $170.00 down the drain!
There are no articles anywhere about troubleshooting or repairing this radio and I don’t have the time to tear it down and dig in to the circuitry to find the problem.
It is a disposable radio with a long term price!
My PL-660 hasn’t died yet, but the very necessary tuning knob failed. My Sony ICF-SW7600GR will likely continue to be my “go to radio” for the foreseeable future. The ICF-SW7600GR doesn’t have a knob, but in my experience, inexpensive knobs have proven unreliable. The only portable with a knob that never gave me a problem is the Sony ICF-2010; it just keeps marching on like the battery commercial. I should be fair to Sangean, I have a Radio Shack DX-390 (a Sangean design) that’s more than 20 years old and the knob still works. The ICF-SW7600GR with some of my “technical ministrations,” (improved AM and FM filters, 1.5 Farad capacitor and “slowed down SSB fine tuning), is my preferred radio (even with its “regular” audio. I will very likely get a Sangean ATS-909X as my “second in command” radio. The ATS-909X is a very good radio but not the most sensitive with its telescopic antenna; I call it a “compact portatop” (portatop from Passport to World Band Radio). One thing that still annoys me about the ICF-SW7600GR is the nine or ten second light, but I believe that I found a way to make it toggle on-off (radio on), and revert to “regular” when the radio is off. As I said previously, the Tecsun radios are a good idea that need refinement/improvement.
From the experience I have got from my Tecsun PL-606’s failed volume knob, I am almost sure that one of the main reasons for rotary encoders to fail is that dust particles can easily enter inside the encoder. PL-606’s encoders have one open side. I suggest that those who still have working rotary volume/tuning encoders would seal the encoders from dust to prevent them failing in future. This should be an easy measure using adhesive tape and possibly other materials.
How did I come to this conclusion? Just a few days ago I decided to open the failed encoder of my Tecsun radio to clean the encoder. Unfortunately that proved not to be easily possible. For this reason I only cleaned the radio’s innards and the encoder’s open side from dust. I didn’t expect this to improve the situation, but to my surprise it seems the encoder indeed improved a lot.
Hi
Thanks for the info much appreciated.
Im sorry to hear about your unfortunate experience with rotary encoders. Ill have to wait and see how the rotary encoder on mine turns out. I agree its a pity the backlight is not more customizable.
The Tecsun PL-660 and PL-680 are a good idea, they just need a little improvement. The dial should be calibrated so that it sounds “tuned” at the correct frequency. I believe that Tecsun should start using optical encoders since they don’t wear out, and could theoretically last almost forever. It would increase the price slightly, but it would greatly increase reliability; and these two models don’t have separate up/down buttons. The Sony ICF-2010 was a little expensive, but its rotary encoder appears to be almost indestructible; my sample still works like new.
Its a well known common issue with the PL-660 that its 1 or 2 khz off when you tune into a station. You have to calibrate it. Yes i know strange and should not be like this but it is unfortunately. Just google PL-660 recalibration and youll get a few diy’s / tutorials how to do it. I performed the calibration and its all good now.
Anyone know if the PL-660 has DSP? I googled it but information is vague.
I looked inside the PL-660 and it’s a “regular” radio with standard and very compact ceramic filters. It uses the standard 455kHz intermediate frequency. I’m considering a Tecsun PL-600 because it has up/down buttons in addition to a tuning knob. I had bad luck with rotary encoders on Chinese radios. The PL-600 doesn’t have a synchronous detector, but the light can stay on permanently and as mentioned it also has up/down buttons.
I just downloaded the PL-660 manual and see the backlight can be set to on permanently by pressing “Light / Snooze” when the radio is on. This is however not possible when the radio is off. Hope this helps.
This feature, like the calibration procedure, doesn’t work with my version of the PL-660.
Yes, the pl-660 is a DSP based receiver.
I looked inside and didn’t see anything resembling a DSP processor or Silicon Labs chip that’s popular in portable DSP radios. It is an MCU controlled radio as is typical of almost all radios currently produced. It did see lower quality ceramic AM and FM filters; this is typical for radios at this price point.
Yes, it is a DSP based receiver.
Hey everyone: )
Yeah so i received my PL-660 a few weeks ago and really love it! Bought on amazon.com. its my first ever world band receiver, always wanted one and glad i bought one. At age 42 its a bit late i know but better late than never haha.
It took me a a week (5 work days) sifting through all the different models from different manufacturers of portable world band receivers and finally i decided on the PL-660.
Reason i decided on the PL-660 is because it has the look i like, large backlit display, built in clock, can show time while listening to radio, snooze, alarm, many bands, auto scan, good sound, use AA batteries, good battery life, compact size etc.
I wasnt too clued up with its other functions and took it as a bonus. My little friend now goes with me to work and returns home with me, its great to have music everywhere i go.
The PL-660 adds value to my life / improves quality of life for me. I recently went on a trip to another part of the country and took the PL-660 with. Sadly it was so remote there was not much to listen to however back in civilization i have a lot to listen to.
Very glad i made the choice to order the PL-660. Mine is black in colour.
The Tecsun PL-600 did get a very good review on the last edition of Passport to World Band Radio. It didn’t get an even better review because its audio was distorted. Some have successfully modified the PL-600 and solved that problem. The Tecsun PL-660’s SSB fine tuning works very well and smoothly in one direction but is very “touchy” in the other. I have had “bad luck” with tuning knobs on Chinese radios, I’m considering the PL-600 because it has up/down buttons in addition to the knob. You also have the choice of leaving the light on full time. That’s something that is bothering me with the Sony, the light goes off after a few seconds. I will probably modify it to toggle on-off when the radio is on and revert to “normal” when the radio is off.
Concerning the Tecsun 660.As Ive mentioned in my reveiws of past posts to this,I bought my first one,and it was a “Black” pl 660.It had real bad “Birdies”/Harmonics right through all SW bands.Strangely enough the Harmonics would follow as I went up or down the frequencies on each band.Louder than any station I received.So I returned it to the importer,who gave me another in replacement and told me he had,no returns from other customers.So I tried this one,and 3 others and yes all the same.I even tried a PL 600 and it had squeeching sounds across the bands.So by then I was at a point of asking my money back,but I decided to try a “Silver” coloured PL 660.I turned it to all SW bands and went through all frequencies and to my shocking suprise,NO BIRDIES at all,no internal harmonics and that was 4 yrs ago and to this day that radio performs as good as my Sony 7600GR and others.About the Tuning knob,yes they do full off but hey,it’s not a problem,just glue it back on or do as I did find a much bigger knob for ease of turning and glue it on useing “rubber” glue just incase you need to get repairs done and the knob has to come off. So in my case I found the Silver model a success. Maybe they were made on a different assembly line in the factory.So if having trouble with your BLACK PL660 try a SILVER one,your problems may be solved !!.
I own the Tecsun PL-660 but I use the Sony ICF-SW7600GR everyday. I consider the Tecsun PL-660 a good idea that needs improvement/refinement. Its audio is pleasant for program listening, but my sample sounds “tuned” only when I tune 1kHz higher than the actual frequency. The Sony sounds “tuned” at the correct frequency. One annoying characteristic of the Sony ICF-SW7600GR is its very “touchy” SSB fine tuning; it’s difficult to zero beat a station or to keep SSB stations from sounding like Donald Duck or the Chipmunks. I modified mine and now its SSB fine tuning is on par with a communications receiver “clarifier.” I reduced its fine tuning range to a little less than +-1kHz; I can now zero-beat a station very easily, and it stays on frequency after the typical warm up period.
Henry,
Could you please give us some details on how to modify fine tuning in 7600?
After considerable testing, I disabled R203 and connected a 18k 1/8 Watt resistor. RV201 is connected as a rheostat, with the “wiper” connected directly to one end of the pot. I cut the wiper trace and connected another 18k resistor where the rheostat trace had been. The wiper now connects to both ends of the pot through 18k resistors. A simple drawing would explain it in a more “eloquent” manner. After installing the resistors, you (very carefully) adjust CT201 for zero beat when the thumbwheel is around its center position. Of course, this should only be done if you have enough experience with circuitry. I’m surprised that Sony didn’t do this themselves; it would have made SSB much easier to tune and the radio even more popular. Now it’s even possible to use ECSS mode when the signal isn’t good enough to “lock” synchronous detection.
A better way to describe it is to install an 18k resistor. The fine tuning thumbwheel resistor is connected as a rheostat; to achieve very smooth fine tuning, you must break this contact . Connect an 18k resistor where the rheostat connection had been. You then set the thumbwheel to approximately center position and adjust CT201 for “zero beat.” There will be some variations with temperature, but this is normal. Let the radio “warm up” before making adjustments. It’s simple but you should be familiar with circuitry.
Its a well known common issue with the PL-660 that its 1 or 2 khz off when you tune into a station. You have to calibrate it. Yes i know strange and should not be like this but it is unfortunately. Just google PL-660 calibration and youll get a few diy’s / tutorials how to do it. I performed the calibration and its all good now.
This procedure doesn’t work with my version of the PL-660.
The only Tecsun I’ve owned with decent results was the 600. The 660 was a disaster (maybe I rcvd a defective unit). I’m sticking with my two (2) DX-398 rcvrs.
Questo è il vero modo serio per fare un comparazione.
Complimenti
My opinion of my two year-old Sangean ATS-909X has changed during the last year now that I have been also using a new Eton Grundig Edition Satellit (same radio as Eton Grundig Professional Satellit). Both radios are very good with external antennas. Using the whip antennas I find that the 909X has better sensitivity on most SW bands than the Satellit. I also prefer the 909X for SW broadcast stations. The 6 kHz ceramic filter on the 909X has sharper skirts and is always more selective than the broad 6, 4, 3 and 2.5 kHz DSP filters on the Satellit. For SSB and ECSS operation I prefer the Satellit with it’s better SSB frequency resolution. The 909X has much better audio overall (it’s a little larger and has an excellent 3″ speaker) and the built-in NiMH battery charger is much faster and a more recent design than that used by the Satellit.
I have a question to throw out to anyone with a Sony 2001D as they are called over here in NewZealand.I put my 2001D into storeage about six mths ago after takeing all batteries out,hence I have other portables in use.But only last week decided to put new batteries into it and power it up.Up untill I put it into storeage it was operating fine.When I powered it up with the two AA’s in their compartment and the three size D’s in their compartment,all I got was a loud “Hissing ” sound and not able to change to any bands or find stations with the tunning knob.When I turned it off a message came up on the screen that said “Error 3”.So I tried everything I thought of to correct error 3.Nothing has improved.I dont have an owners book with it,so can anyone advice me what “Error 3” may be please.It certainly is not operational.It has not been dropped and it was stored in a dry place.So if anyone can advice me on the problem and how to fix it,reprograme or what ever it needs I would really appreiciate it thanks.
According to the Sony 2001D (ICF-2010) manual, “Error 3” means the radio is not detecting a power source.
I have the Sony ICF-SW7600GR and the Tecsun PL-660. The Sony is a more robust design, the Tecsun does have a more pleasant and “mellower” audio, which is more pleasant for program listening. I stay with the Sony even if its audio isn’t a strong point; the ICF-SW7600GR is an excellent radio. I used it to hear ham radio contests from one coast of the U.S. to the other with its built-in whip antenna. I also heard hams from Europe and South America very clearly using only its whip antenna. A new radio that I’m interested in is the CC Radio SkyWave SSB. It was just announced a few days ago, and the specifications look impressive. It would great if it were also reviewed and compared to the others.
I have a Sony 7600gr that I really like. How long should I expect this particular radio to last if it’s well taken care of?
currently i’m using Tecsun Pl-880 and i am very happy for it performance.
Namaste.
Thanks for the review with study.
You forgot to mention one characteristic of Tecsun-PL660. It has AIR band which no other radio has
I have Tecsun PL-660 since last two years.
It’s battery eliminator stopped working soon after I got it . The batteries drain in FEW hours. I tried this with new batteries, recharged batteries, but every single time it does not give me more than 4 hours.
What may be the reason? How to rectify it
I purchased it from HongKong and using in India where I do not know any Tecsun qualified technician.
Please help.
I have a tescun pll660 it needs to be modified in short wave single side band dection it needs noise reduction filter built in and an earth clip on the aerial
Very good information. I’m looking for info on setting presets however. I was able to enter one preset and now the radio continues to enter the first preset every time I try to enter a second station. Do you have any ideas as to what I am doing wrong. I am trying to follow the instructions step by step.
The Tecsun’s memories are very simple, they increment automatically. The Sony ICF-SW7600GR is slightly a more “hands on” experience. With the Sony, you choose a “page,” and then press “enter” and a number from 0-9, simultaneously; the thing beeps and the preset is stored. The Sony’s memories are non-volatile, the Tecsun PL-660 loses all its settings after a while. The Sony only loses its time after a few minutes. I installed a 1.5 Farad capacitor in the Sony, and it didn’t lose its time settings after more than five hours without batteries. I stopped the test after 5 hours and fifteen minutes, since the clock showed no signs of giving up. The Tecsun PL-660 also has pages, but the radio assigns the next number automatically.
I had the same problem until I realized I was omitting a step. Check your instructions again.
Weak whip antenna performance is typical of Sangean designs. Passport To World Band Radio agreed with this assessment; but Sangean radios usually have good AM RF sections. If you have the space for an external antenna, Sangean performance is usually very good. Tecsun’s PL-660 is very sensitive, and a little noisier than Sony’s ICF-SW7600GR. After changing the ‘7600GR 455kHz filter for better symmetry and replacing the 280kHz filters with 150kHz units, the performance is impressive. I now hear FM stations that I didn’t know were there before.
Well, this is a critique of multiband portables. The Sangean ATS-909X wins hands down on FM with the whip antenna. On the AM broadcast band the 909X is very good, but bettered by some Sangean AM-FM radios equipped with built-in and larger ferrite core antennas. For shortwave listening the 909X excels with an external antenna, but not the built-in whip antenna. It sucks on SW with the whip antenna. I love the 909X SW ceramic IF filters and memory functions. For long wave reception I will defer, because there is not much LW for me to tune here on the US west coast.
I own the PL-660 and the Sony ICF-SW7600GR. After using both radios, I choose the ICF-SW7600GR as my “go to” radio. I also have what was considered “the best portable ever,” Sony’s ICF-2010, but the ICF-2010 is a little large and heavy. Unfortunately, the ICF-2010 tunes in 100 Hz steps without a “clarifier.” The PL-660 is a very good platform, but it needs work. SSB fine tuning works very well and “smoothly” in one direction but it’s very “touchy” in the other. The PL-660’s IF filters are asymmetrical; most ceramic filters are asymmetrical, but the PL-660’s narrow filter could be better. Sony’s ICF-SW7600GR filter is also asymmetrical, but it’s better than the PL-660. After a long search, I found a 455 kHz filter with good symmetry, or as good as I’ll get without a DSP IF, and small enough to fit in a small radio. I also plan to get 150 kHz FM filters and match them for better FM. The Sony’s SSB fine tuning is also “touchy,” but better behaved than the PL-660, and more symmetrical. I’m considering “slowing down” the ICF-SW7600GR SSB fine tuning since the circuit is analog. The Sony is also quieter than the PL-660. The Sony resembles a “boutique” radio while the Tecsun resembles a “mass market” product. The Sony is less “flashy,” but uses better parts as is typical of “high-end” brands. I also wish the -7600GR had a knob, but I can live with its compromise of a non-muting set of tuning buttons and a faster muting set given its performance. The ICF-SW7600GR lacks a signal meter, but I could install a bicolor LED as a meter; it would transition from red, a very weak signal to green, a strong signal. I think “hot rodding” Sony’s last shortwave radio is worth a few dollars. I agree with Passport to World Band Radio and their high opinion of this radio. The Tecsun could be better if the company invests a little more money on its platform.
Sangean ATS-909X
Since everybody is hammering so much on the only weakness of the Sangean ATS-909X, how about testing and comparing the ClearMod version from RadioLabs (http://www.RadioLabs.com/products/receivers/ats-909x-mod.php)? Does the ClearMod upgrade remdy the situation, is it worth the extra dough? How does the ClearMod upgrade impact and change the review and recommendations above?
Great review! I’m a newbie to shortwave listening but I’m a long time radio fan, having worked in the FM field. Radio is my go-to for pleasure. After reading your review and others, I went with the Tecsun PL 880 for the quality of sound. But I must admit, I was disappointed to find that there was only a + or – switch for Bass. To me that’s inconceivable! I now know, I should have paid closer attention to the PL 880’s audio features. I just wrote to Kiwa Electronics to see if an upgrade would be possible. For the increasing numbers of us (the getting older crowd) who have mid-to-upper hearing rang loss, a quality variable tone control would make a wonderful addition! I love bass with some music but oftentimes, especially with speech, bass only muddies the waters. I’m sure many have gone over to the bright side as I have.
I own the Sangean 909x. I used to own the Sony ICF-SW55. The ergonomics of the Sony are terrible. That small screen was a joke. I sold it for those reasons. I didn’t find its performance that great either. I bought the 909x when it first came out a few years ago. The radio is perhaps the best looking radio I’ve ever owned. Performance-wise, on MW and SW is not great. FM, on the other hand, is superb. My Kaito 1103 is perhaps the performing radio I have ever owned. I am now looking for something for the office. I have had my eye on the Grundig 750. But after this review, i might consider the Tecsun PL-880 instead. Great review. Keep up the excellent work.
excellent reviews worldwide receivers. For two months, held an international meeting amateurs and one of them to determine buy, yet choice fell on the 909X, looks best mechanically produced, and I tried it on the antenna MLA for sw. Thank you all for your excellent reviews of all the receivers. 73 OK2AQA Marcel Czech Republic.
I own 3 of the 4 radios tested here (no Sangean 909). I also have a few others. Some reviewers mention performance variances among otherwise “identical” models. I’ve traveled with a Grundig G6 Aviator. This mini portable generally offers better sensitivity than either of the 2 tested Tecsuns or the Sony 7600GR. The main drawback with this radio is its small speaker and limited audio.
All things considered I’d rate the Sony as my favorite portable (unless the definition of a portable can be stretched to include the E1XM). If Sangean can adequately address the sync issue, I’ll surely buy one.
Great and thorough review. I recently got a PL-660 to replace my aging ICF-SW7600G. It’s a great little radio and has several features that I wished for on the Sony such as tuning knob, clock visible when the radio is on, etc. For the price, it’s all I need. Thanks for helping me make this decision.
I chose the 660, and the 880 isn’t bad, but not just for sound: I like being able to use REGULAR batteries in a set, which the 660 can use, but the 880 can’t. And the 880 case appears to me (I have examined one up close) to be a bit less robust than the 660. I also prefer a SILVER case, (which is the colour of my 660) because they don’t bake radios outside like the black cased ones do in the Sun. BUT, I will say, the 880 is a beautiful radio.
Fantastic review and whilst I know the article is an older one people will still read it when looking at a portable SW radio.
With this in mind I would like to make the following comment about the PL660. You say it is bulletproof and boy is it! Mine has been dropped, kicked and overwise abused and it’s still going strong.
Most remarkably it was knocked into a bucket of water, plugged in and powered up and was there for a good couple of hours fully submerged before I realised.
It wasn’t long good for a week or two but after 3 or 4 weeks I have it one last try before binning it and hey presto it came back to life! Ok the volume pot is now a bit scratchy but other than that it’s working just fine.
Want a radio that will take the general abuse of travelling – this is it…
Upon reading your message concerning your PL660 Danny,made me wonder a little.I have a small portable radio collection,and even when I have been out in the Great out doors Camping,Ive always guarded all my radios with the utmost care.I love my radio hobby so much that I look after them as I would a Camera,you just dont drop them or have them near any dampness,or in the direct sunlight.It takes alot of my hard earned money to ever afford to buy such great radios.They are not toys or there to be abused in any way.I do take my DX hobby seriously !!
$170.00 for a pl-660! Glad I got the 880 for $159.
Which one is the best for FM-DX?
Thank you Tomas. Ask a question again.
I want to listen to VOAChinese because it has some special programs for China.
VOAChinese satellite TV program is broadcast on Ku-wave band(11.7-12.2GHz)
Is there any portable device that can listen to Ku? Model?
I’m living in Beijing, China. It’s well known that some internet and radio programs have been blocked strictly by the Chinese government. I need to listen to some voices from other countries’ radio programe like VOA Chinese whose opinions are different from Chinese authority(Please referring the frequency of VOA Chinese http://www.voachinese.com/program-frequency.html). Including but not limit the devices mentioned above/below, I’m not sure which radio device is more suitable for my situation. And If the device is portable, it would be great.
Besides VOA Chinese radio program, there is VOA Chinese satellite TV program. I found such device like Eton Grundig Edition Satellit?http://www.universal-radio.com/catalog/portable/0050.html?. Doese anyone know that whether this deivce could receive VOA Chinese TV or not? If it could receive VOA Chinese TV, I prefer to choose this one. Because comparing radio device, it’s more difficult to block satellite signals by using TV device.
Thanks.
Just buy one of the Tecsun DSP models from JD.com, for example PL-310ET or PL-660. The “Satellit” is just an old German radio name that they bought to market their models with, it doesn’t have anything to do with satellite TV.
If your English is good enough you can listen to VOA or BBC World Service in English, I think they don’t even try to block those. I had no problems receving BBC in English in rural Guangdong with a PL-310ET at least…
Thanks for sharing these informations, of invaluable interest for a real naive like me in this field.
Following your review, I bought a Sony 7600 on Amazon and expect it to be at my door in a few days
I will use it on a boat to get marine weather forecasts on FM, LW and SW, but not only. I would like to record these forecasts on a simple voice recorder equipped with an external mike jack. But I am not sure the signal of the line out (245mV, 10 ohms), aimed at old cassettes recorders, would suit the in connection of the digital recorder. Would you know the answer to that question?
I read in you review you record from the sony on a recorder when on the field. What kind of recorder do you use?
Regards
Francis
Hi, Francis,
Yes, the line out on the Sony is at a perfect level for using with a good digital recorder. I have used both the Zoom H1 and Zoom H2N handheld recorders: http://amzn.to/1DxhbjD
FYI: Make sure that your audio patch cord to the recorder is shielded. Most are these days, but if it isn’t, you will pick up more noise in the recordings.
Good luck and let us know how you like the Sony! Good choice.
Cheers,
Thomas
Hi,
I would like about a radio with RDS,similar to the SANGEAN ATS-909X,but less heavy,not 1 kg.
Can I get it in Spain?
Thanks
L
I am interested Tecsun PL-660 and PL-880. Particularly the 880.
My concern is that it sounds like these radios might use unusual batteries that might be hard to find in a few years when they are no longer manufactured.
As nice as these radios sound, I want a radio that just use good old fashion AA batteries or something similar.
What do you recommend?
Hi Earl.Im quite puzzeled reading your short letter concerning that the batteries used in the PL 600,880,you say are unusal,and that they may not be manufactured in a few years time.You talk about the “Good old fashion AA batteries aswell.
Well Im having a problem trying to understand what this is all about??I acturly own the PL660,I use rechargable AA batteries in it,and when they go flat,I just recharge them via the rechargeing inside the radio,or I have 4 spare rechargable batteries already fully charged,and I install them into the PL660,to keep it going on a known station of interest.The radio does have a switching so that you can switch it over to ordinary alkaline batteries,if you would rather use them.Running the radio on 1.2 volt rechargable AA batteries compared to the full 1.5 volt AAs acturly makes very little difference with my PL 660.I dont see the AA batteries ever going out of production anywhere,because so many devises use them.
Thank you, that is very useful information. I just wanted to make sure that I can use traditional batteries.
Hi, Earl–The only radio in this review that uses something other than AA batteries is the PL-880. While it’s not as common as the AA, I have found this battery locally at a battery store. They are also widely available on the internet. Universal Radio sells them (http://www.universal-radio.com/catalog/portable/0088.html). The good thing about these batteries is that they have excellent capacity once charged. But again, the PL-880 is the only Tecsun model that uses them thus far.
-Thomas
The batteries are called “18650” and they are actually very common and have been around for a long time now – countless laptop batteries consist of 18650s, they are being used in LED flashlights, electric cigarettes and a lot of other applications, 18350 through 18650 are the most common lithium cells around and they’re not very likely to go out of stock anytime soon.
You can buy them at almost any electronics supplier or order them from Amazon quite cheap.
Just one quick point, LiIon cells come in two varieties, protected and unprotected. Unless the item receiving the cell specifically states that it can use unprotected cells, never use them. Stick with quality protected cells and you’ll live a happier life.
Excellent and comprehensive review – thank you! I’ve had my PL-660 for several months, and thinking of buying a PL-880 for a backup (and keep on the boat). The PL-660 has been a great radio so far. Again, thanks for the great review!
Hi,
Interesting how the reviews and comparisons contradict each other so much! I read all of them before purchasing a black one then re-read the previous post comparing with a Tecsun and my experience has been the opposite. My Tecsun PL-880 was way too bassy and vibrated the antenna internally. My ATS-909x has been flawless BUT….There is one issue I failed to find mentioned in the numerous reviews I read that is specific to the black model.
The contrast of the markings of the meter bands on the numeric keys is is too low and almost unreadable. Even with my glasses on a strain to discern the numbers. Keys being medium dark grey and the m band numbers a greyish blue. The white model has black m band and white alpha numeric markings that appear quite easy to read. This issue is especially problematic for those like me who need readers glasses [I wear 1.5 readers] and low light exasperates this in my case.
It appears Sangean uses different keys on the black and white and by making online comparisons I can see the white keys have better contrast.
Hope this helps some like me who missed this issue specific to black model and those of us with poor vision.
Well in answer to Travis’s message I can say that I acturly ordered a “black” ATS 909X but to my supprise a “White” one arrived at the electrical shop where I ordered it.I asked them to send it back because I had my heart set on a black one.Then I received an email to say that the importer only imports “White” ones,so I had no choice.But Im so glad I did settle with the white one,it has outstanding performance on FM and HF SSB.I dont listen much to FM,but it does pull in those distant stations very well,far better than my Tecsun PL 660.But yes the telescopic antenna is not there for SW listening,I agree.From what I can make out,its only there for FM listeners.If an outside source antenna is connected to the imput on the side of the radio,I find it works just as good as my PL 660.The difference is that the Tecsun PL660 is “Over sensitive” on the SW bands..It picks up all local electrical interference aswell.Where as my new ATS 909X doesnt pick up that interference at all almost as if it has an “in built” noise blanker.Ive compared side by side the PL 660 and my new white ATS 909X and sw/SSB signals are on a par,useing the same outside 100 ft long line antenna.No over loading,no stations cutting in anywhere.Just good strong signals on my ATS 909X.Also I must say yes,the lettering and numbers on the button keys are very easy to read,I too use reading glasses,ans find no problem,so Im very pleased that I did buy a white one,with a very clean finish.One thing I shall add,is that I always put a protective film over the screens of all my radios and portable scanners,to stop all scratches.You can buy this easily at Phone shops or the “$2 shops” ( Bargin shops) if you have them in yr country.The protective film sticks very well once you have cut it to size.thanks.
My very first impression of the Sangean ATS 909X.Firstly,I ordered a Black one through an Electrical appliance shop in Auckland city,New Zealand.They phoned me to say it had arrived,and I could pick it up and pay for it.So off I went to the shop,only to find it was a “White” one,so I told them I was sticking to the Black coloured ATS 909X.I asked who were the Importers of it.It turned out that the Importers were local,to Auckland.I emailed them when I got home to find out why they sent a White one.Their reply was that they only import white ones into the country.I couldnt understand why.So I decided that because I needed it, because it is Alfa Numeric,tagging stations etc,I would buy the white one anyway.
Well here is my first impression of it after I powered it up and got it running.The ATS 909X certainly does not have a dedicated FM circuit.I tried it on several distant FM stations with the telescopic antenna and I could barely hear one,and it was quite distorted when it acturly received it,compared to my trusty Tecsun PL 660,the FM distant stations are there in the distance,but the ATS 909X couldnt pull them in.Also if the Wall power supply thats “AC” ,not “DC” out put,is connected while on SSB,it puts out quite a loud hissing sound.Perfectly okay just on battery power.The other thing I noticed is you have a choice between Alkaline batteries or rechargables.The rechargeables times four only give you 4.8 volts,but the alkaline give you a full 6 volts,yet the radio seems to work just as well on either as far as volume and sensitivity goes.Took me a while to work out how to save frequences and lable them Alfa numeric.But compareing it with the Tecsun PL 660,it certainly is not as sensitive on Short wave HF.The SSB tunes in very nicely,even with the indented tuning wheel.I wont be takeing out the indent spring in mine,I can get used to the little clicks it has.The Speaker sound is very bassy compared to my Tecsun,if I turn it up too loud it vibrates a bit,so yes it has a very bassy speaker even with the tone switch adjusted.The AM gain is varrible but does not give much change to the outside antenna gain.It does not over load at all with the outside antenna contected on full gain,on AM/SW.Anyway the main reason why I decided to purchase this very expensive portable gen coverage receiver is so that all the Utility HF ,SSB frequency memories can be entered in Alfa Numeric,and labled in pages.The FM does have the Radio Data system that I noticed works very well giveing out all types of info according to the station.But Im not really an FM listener.Any way would anyone know if the Black radios are in fact any different to the white ones.I noticed that the Software version of this one is stated at 29.1 verson.You press “Enter” when radio is turned off and it gives out the software version on the screen.I would like to know what the 29.1 means,as in date or batch of manufacture.
After reading all the pros and cons of the Sangean ATS 909X,I have decided to go ahead and order one via a local radio/electrical shop here in Auckland at the New Zealand price of $499.I know its very expensive and money like that just doesnt fall out of the sky.I have the Tecsun 660,really only a very basic portable receiver,of which I needed to try several befor I found one that didnt have that horrible Harmonic internal generated noise.But you can not “Tag” stations or frequencies with a Tecsun.I owned the Sony SW 55 for many years of superb listening,and that portable could indeed Tag stations.So Im buying the “over priced” Sangean to replace my old Sony SW 55.For me,out of all the reviews,Im not so concerned about the lack of sensitivity on the telescopic antenna,as I have a Long line antenna anyway.And I read that the Mods to rectify this problem with a ballun will ruin receiption on FM.So whats good for SW,is not good for FM.So I plan to just leave the ATS 909X as it is,and concentrate on all it’s features and bells and whistles and enjoy them all.The ATS 909X has a large screen,and quaility built design.From what I can see in photos,and reviews on the internet,I should be satisfied with it for my SSB DXing of Utility stations world wide.If the indent spring causes a problem on the tuning wheel,I shall remove it.But I need to see for myself if this indeed causes much of a problem when useing tuning steps to refine SSB on offical frequencies. I shall follow up at some stage with my own report on the radio after I have bought it.
This is an excellent review which answers many questions. I have used a Sangean ATS-909 for years and I am still very pleased with it. I would agree that the ATS-909 whip antenna works poorly for shortwave, but I have received very good results with the included Sangean reel antenna. Do the external antennas included with the Tecsun PL-880 and PL-660 improve reception to a similar degree?
All very good comments and this is what it’s all about,compareing apples with apples,radios with radios!Im a very long standing SSB DXer.I love listening in to the most distant SSB utility message on HF,and noteing it down.I do have my most favourite SSB frequencies in the memories of my radios including the Tecsun 660,Sony ICFSW 7600G.I have old National Panasonics like the DR49 still going strong after 40 years.But for me Im not a SW listener.Thats why Ive found it very hard to find a portable receiver that will tune in a SSB station that is acturly readable.There are quite a few good receivers out there,but their SSB clearity is very poor.As far as Im concerned,a True SW radio should include all the bells and whistles,and SSB mode.Digital tuning and BFO or tuning steps to receive SSB clearly.Im very happy with my Tecsun PL660.After trying 4-5 of these with very bad internal harmonic problems,all black in colour,I finaly found one that works fine,it’s a Silver one!!.
But I have one problem,it’s with my old Sony SW 55.A great radio that you can tag stations with its Alfa numeric screen.Its now dead after about 15 years of almost continues use.The capacitors have dried up,and acording to one message on You Tube,it’s a very common thing that only happens to that model.It simply will not power up any more.Ive tried many times,but yes it has finaly died.So thats why Im thinking of buying the new Sangean ATS 909X.I know about the mis match on the antenna.What happened at the Sangean factory when they were on the test bench…I wonder.But this can by modified and fixed, according to reveiws.What I like about the ATS 909X is that it,like my dead Sony SW55,you can “Tag” stations,Alfa numeric.Instead of having everything noted in a note book,you tag stations or name the paragraphs, eg “AIRCRAFT “then select pages with frequencies related to that name.I had arround 500 memories listed in the SW55,Marine,military,aircraft and so on,all HF SSB.
So thats why I’ll go with the Sangean ATS 909X.I have not owned the 909 model,I belive they are not available anymore.I live down under in little New Zealand.Not part of Australia.We have very limited supply of any SW portable radios here.We rely on importers,of which there are very few.There are really no “Radio” shops here,except JayCar,(Ausi owned shop),who only stock a very poor selection of SW radios.But for the true DXer,New Zealand really has no shop to serve our greatest and loved hobby! I would wellcome any comments please!!
You might want to consider having the SW55 recapped. The SW55 is one of my favorites. The ported speaker is a nice bit of audio engineering!
Thanks for your reply concerning getting the Sony SW 55 recaped.I dont belive there is anyone able to do that for me here in New Zealand where I live.It would be one of the most differcult jobs to do.And to have the caps available aswell.The ATS 909X is a much updated radio,as long as I can get the telescopic antenna mis-match fixed.Maybe I can do that myself,Im a Ham.But as far as the Sony 55 goes,Ive opened it up,and it’s not for me!I’ll treasure it in my collection of older portables etc.Maybe I should have it framed on my wall!! Alas,I will surely miss the SW 55.The SSB always quivered/shaked.but I got used to that,cant expect every receiver to be perfect.But this one was almost in daily use,untill just oneday I turned it on,to find that it would not power up,and to this day,it will still not power up.Very poor of Sony.
James: The 909 is a fine radio, as well. For a couple of bucks you can add a toroid and take care of the mismatch. While still not as sensitive as the SW55, the 909 is a fine radio with really nice audio. Greg S. KJ6MC
Fantastic review, Thomas. Based on your assessment that the 909 does so well on FM and since FM is my most common band to listen to, I’m tempted to get the 909 to replace my Sangean WR-2. Plus the 909 has a smaller footprint. Thanks again.
Hello! I own the Tecsun PL-660 and PL-880 and the Sangean ATS-909X. While I don’t have the Sony, I do have a Sony 2010, SW55, SW100 and SW77. Thomas is correct about Sony quality. The Sony products especially the SW55, are built to last. I love the ergonomics of the PL-880, the fine tuning knob is a joy to operate and with the bandwidth choices extremely flexible. The 909X was a disappointment, now– much less so. Even with the RadioLab “Clearmod”, the sensitivity was far too weak, especially here on the west coast of North America. The 909X’s saving grace was a 4:1 balun mod that I did about a year ago. It’s pretty simple to accomplish and (as I understand) helps cure a huge impedance mismatch between the whip and the front end. The cost was cheap (about $7), the results impressive. And the audio quality from the 909X speaker on FM is a joy to behold. Now, if Sangean would incorporate sync detection, the 909X might just be my favorite.
The best / most expensive Receivers / Ham Transceivers are essentially useless without an external antenna ;).
Last year I made a review for our radio club magazine about these foer portables. Owning the PL-880 and the ATS-909x I borrowed the ICF-SW7600GR and the PL-660 form our club members to make a direct confrontation both on the whip and a external Kaz antenna via a four way splitter . I spend three full days on testing everything I could imagine.
I mostly do agree your definitions, but… There are some important differences between the SW frequency bands to be noted on sensitivity part between the radios! Also the quality of the decoded sideband audio was very different. In that fact the PL-660 and more so the PL-880 are very “digital ” sounding and the ATS-909x was somewhat better but could not stand up to the analog ICF-7600GR quality. The PL-880 has awfull AGC pumping when signals are still fairly strong. In fact I sold it because I could not bare listen to it any more.
In my opinion Sangean has made a design fault with a impedance mismatch of the antenna whip coupling to the board and this degrades the reception sensivity in a marginal way, but can resolve this in a simple way.
Best strong signal handling was done by the ATS-909x and also the audio over all was the best. It also had the best FM band reception sensivity and a decent RDS detection wich none of the other radios do not have.
I think you have to see the complete picture and to make a choice of radio. Some like to listen to SSB and others to AM broadcast and this is a determinating factor on what radio to buy as they are all different in more than one way.
Just my 2 cents…
Very useful website. IF bandwith modification of ATS909X
http://webpages.charter.net/n9ewo2/ats909x.html
I own a version 8820 unit of this receiver and have not experienced this problem. My only complaint about this receiver is that its synchronous detector [with its 4 khz (max) bandwidth] actually makes AM signals sound worse.
hi guys i’ve read the post i’m from Pakistan.I purchased ats 909x and it seems quite impressive because it has good fm reception but big problem is when it comes to dxing it has less sensitivity especially in fm.However it also works good in am and sw.Well to be honest i realized that if you drop a reciever accidently there are marks and scratches ,i wonder if there will be a microchip problem inside.By the way,someone has advised me to purchase tecsun pl660 which is quite cheap and i wanted to know if there is any unbeatable performance than 909 x
usman khan
karachi,pakistan
Too bad you didn’t test/demo strong SSB signals. This appears to be…well, let’s say a really bad omission.
I almost pulled the trigger on the PL880 (for whopping 270€ (!) because it comes with a stupid plastic box, otherwise 180€ which ain’t cheap either) but then I watched a video by hamrad88 on YT where he compared SSB reception with his Satellite 750 and complained about the noticeably wobbly/warbly sound (if it was an analog radio, I’d say something is slightly modulating the VFO, or it is generally unstable) on the 880. I checked pretty much all other videos demoing SSB reception on the 880 and each of them had that more or less of that “trademark sound”.
That and the really bad distortion due to the slow onset of the AGC makes the 880 the worst of all the cheapos on SSB, it’s not very enjoyable to spend a whole evening with those quirks. This is really sad because I found the bandwidth choices and the potentially good sound would really put the 880 apart from all other portables but now it turns out they basically botched the whole SSB part big time.
It’s 2015 and there are no news about any improvement in this regard, so I guess it won’t happen.
If you are looking for an inexpensive radio that has decent SSB audio, go for the PL-660 or the ICF-SW7600GR.
Concerning the poor reception of the Sangean ATS-909x with whip antenna.
Goto:
https://uk.groups.yahoo.com/neo/groups/ATS-909X/conversations/messages?messageStartId=331&archiveSearch=true
And find a way through all messages concerning a balun 20:5 turns on ft37-43 ferrite core using #26 enamel wire, modification
This will cost you a lot of time to read. The modification itself took me 2 hours.
With a superb result. The ats-909x is not deaf at all after this modification and can now be used in- and outside with the whip antenna, and can compete with the other 3 portable receivers (even with my Lowe HF-150, concerning sensitivity).
Total costs: 3 Euro and some time to implement.
Do it and you will be surprised.
Success, 73’s de
Wim, from the Netherlands
Hi Wim!
Could you tell if that mod affected the FM section?
As for my ATS909, Improving the whip contacs and isolating it from the speaker (-) terminal (the antenna’s pin on the PCB shorts to the terminal), Shortwave reception is HOT, but FM has increased noise level to such as Auto Scanning is not possible.
Best Regards,
Moshe.
I’m looking for a radio and can’t decide between the PL-880 or S-2000.
The S-2000 certainly looks more the part, but I’m worried that it’s been out so long, should I wait for a replacement model, or should I go for the PL-880?
Does the newer technology in the PL-880 make it a better radio than the S-2000?
Any help greatly appreciated 🙂
Hi Richard,
As i replied before, i don’t own the Pl880 but i have the S2000.
It is A great radio,fun to play with, and when you take it outdoor you don’t need anything but the radio itself, as it receives very well with it’s own telescopic antenna.
One thing to look at is Tecsun’s poor quality control, and as I mentioned in other reply: It looks as Tecsun uses A very poor quality soldering tin that tends to break and act like powder.
They have gread radios, but once you get one, best thing is to resolder it…
Best Regards and Good Luck,
Moshe.
Excellent, Thank you for your reply. It’s certainly something to think about. It might put me off Tecsun altogether 🙁
Hi Richard,
I didn’t ment to get you off tecsun.
Belive me, I really enjoy my S2000, It’s fantastic! I just had to resolder it after some fault occured. Not all Tecsun comes bad.
Batteries are still over 2/3 level after 4 months of daily use.
All the best,
Moshe.
I’m just struggling to decide, but think I’m more decided on the PL-880 again.
It’s cheaper than the S-2000 but the technology is a bit newer.
I do like the S-2000, it’s the better looking radio, but probably would also like the advantage of the PL-880 being more portable.
Kind regards,
Richard T.
I have a CommRadio CR-1a, a Tecsun PL-310 and some Eton/Grundig portables. I find that I spend most of my listening time trying to find stations strong enough to receive, and that includes using the CR-1A connected to a Wellbrook loop. I’d be interested in your opinion of the auto-scanning ability of the four radios and how well it works. The CR-1a is a beautifully simple radio and it auto-scans quite well, up or down, at a user-settable jump rate. But it is not designed to stop at strong signals nor to hold them for later retrieval. It also loops inside each band when auto-scanning (as opposed to continuing up or down the bands), though you can choose whether to use the amateur bands or broadcast bands. I used to own the Sony model you reviewed and it is a superb receiver, if a bit complicated. I never cared for its audio though.
Thanks for a superb review!
I have an older Sangean ATS-909 which is currently locked up. Apparently the solution is to remove power, and wait a few days…
While waiting, I dug out my backup receiver: Tecsun PL-390. Bought it for use as an alarm clock / radio, a few years back.
It certainly seems more robust than the 909 (hey, it’s working!) But I miss SSB. So now I’m wondering whether to retire them both, and buy the PL-660. Thanks to your article, I can now make a more informed decision.
One point: will this excellent comparative review of portables, be followed by a comparison to Tabletop Receivers? CR-1 vs R-75 vs …?
Hi Alan!
look at the bottom of your Sangean: you will see 3 holes marked: A B Reset.
Use toothpick to press the Reset switch to unlock your radio.
Good luck.
Moshe.
I have found this radio comparison very informative and for me has been published very timely as I start to gain a bit of an interest/understanding of this whole new field.
After reading this and many other reviews I felt compelled enough to put any order in for the Sony SW 7600GR ……… hopefully arrives by father’s.
I am waiting expectantly to receive it in the mail and hear first hand about the good wrap this unit gets building a long term relationship with it.
Thank you for one of the most informative comparisons across a set of radios that I have read in a very long time.
73,
Jay
Friends, I’m from Brazil, I’m not expert in radios, but I’m in love with them and am getting a model among these four to listen to AM / FM mostly. I would appreciate an opinion of you.
Thank you.
Dear All,
I am from Mumbai India. Technically I know nothing about radio. I am more interested in FM an AM.
(SW sometimes).I want Good Sound Clarity Noise Free.It should also have Sleep Timer.Can you pl pin down the best model as I would like to use by Bedside?
Regards
Jaiswal
I own three of the four radios reviewed here (the one I don’t have is the 880). My main interest is DX-ing in general but mainly on SW. There is something that needs to be said about the Tecsun PL-660, and I’ve always wondered why none of the reviews I read mention this. The 660 has a flaw which (as far as I read on a mailing list) has been acknowledged by the Tecsun engineers. The DC-DC converter inside the radio (NOT to be confounded with the external DC power source!), which supplies the variable voltage needed for the varicap diodes inside the tunner, generates a strong spurious signal slowly moving up and down between 900 and 1000 kHz. Moreover, there are numerous harmonics going well up into the SW bands.
If the MW or SW bands in your area are crowded with strong stations, you may not notice this spurious signal. But medium strength or weak stations will be periodically muted for a few seconds, each time the signal crosses over their frequency. I may be picky but for me this is unacceptable.
This problem (together with some other annoyances on other models) made me decide to stop buying Tecsun radios. I know all radios have flaws. But some of them can be overcome using external help. I don’t mind 909X lack of sensitivity: I use external antennas. I don’t care too much about the strong 2nd order intermodulation products noticeable on the 7600GR: I can get rid of them using a preselector. I can’t, however, do anything about the spurious signals on the 660, and it’s so frustrating because it really is an excellent radio in other aspects (excepting LW and MW).
About the Tecsun 660 spurious signals from within the radio,I acturly tested 4 of these that I had bought via an importer,and returned them with a full refund.All had the same problem.Even one 600 had the same problem,more amplified when useing SSB.All of these radios were acturly black in colour.I finaly found one with no Spurious noises at all,its the one I own now,and it is a Silver coloured one.Also some one mentioned that inside the 660,there are two back to back diodes,that are very near the telescopic antenna rod,and can easily become cracked,causesing no receiption from the antenna.Well I opened mine up to take a look,I found no diodes near the antenna rod at all.In fact I noticed that the back of the circuit board faces the antenna rod with nothing in its way.
Hello, All,
I read and listened to the different radios reviewed in this thorough assessment. I own 2 out of the 4; 880 and 909x and I put the 909x above the 880. Like a few others here I use the whip and/or provided spool antenna on the 909x and charge simultaneously. In this case tech beats the 880 with the same type antenna.
By the way I paid $125 for the 880 shipped and $179 for the 909x shipped, both brand new from eBay. The price for the 909x is a driving factor when making my determination. I’ve seen the 909x priced as high as $400 and the 880 as high as $200. I will say they both, or in the case of your review, all 4 are great radios and have their purposes. When it comes down to it, every person buys a radio(s) for a specific reason(s) or feature(s). In my case I enjoy the hobby of SW and MW.
If you are a licensed HAM like most of us, if not all of us here, we all have a different base, portable and handheld than the next guy but it’s always nice to get a different perspective from others like getting a repeater check from across the country. 73!
Respectfully,
Mike
I have three out of these four radios and as a long time SWL, I have to point out a few things about the 909x that bug me enough to keep me from buying it.
Price is a big deal, being ~$100 more than the competition, ESPECIALLY since the 909X is the only high end portable receiver without synchronous detection. (That’s a big one!)
Very little explanation of what the DSP doing.
A 40 Hz tuning step is still to wide for comfortable ECSS, regular sideband listening or decoding digital signals (100Hz was a problem for the 2010, 50 a problem for the SW77, but 20 was tolerable for the G6.)
Finally, the sensitivity. I mostly use a 30-40″ wire or an LP-1, but there are many situations where the whip is the only option.
Overall, it’s a beautiful looking radio, just behind the times feature-wise, overpriced, and in some cases, badly engineered (40Hz? Either make it 10 or 100 with a fine tune.)
Mark,
The Sangean ATS-909X is commonly available for a little over $200.00 on amazon and epay, and sometimes I have seen blowouts for as low as $179.00. The PL-880, at $149.00, is only about $50.00 cheaper, not the $100.00 that you claim in your comments. As far as the DSP, I don’t know of any of the manufacturers of currently available portables explaining what the DSP does, including Tecsun.
I don’t know why Sangean has a 40 Hz fine tuning step, but it has never been a problem for me tuning in a SSB station. Many reviewers consider the ATS-909 and ATS-909X one of the best portable radios around for ham and utility station listening in SSB.
A huge factor for me in price is unit to unit quality variation, and overall quality. the 909X is very well put together, and displays a consistent level of quality. However, if you go on the Yahoo group for the Tecsun PL-880, you will find that many of us (myself included) had to go through 2 or 3 radios to get a good one. I donated one to Dave Zantow’s site, “Dave’s Radio receiver Page” for him to review, and it arrived with a non-functional tuning encoder, and the antenna was loose. We had to get his sample replaced.
The most recent entries in the group deal with the problem of defective tuning encoders, and there is a copy of an Email from Anon.Co acknowledging the poor quality and problems with the tuning encoders in units produced to date. Supposedly Tecsun is addressing the problem, but that does not help owners of radios already in the field.
I would rather pay a little more for a quality product that will be around for awhile trouble-free, as opposed to playing the Tecsun defective radio lottery.
John
Hi john,
I have to agree with you, as I have the 909 and it is well built (inside and out). I ahe fallen in what you called “Tecsun defective radio lottery” as I ordered the Tecsun S2000. On the first day of use, the backlight started dimming erratically (like poor contact) and went dead. I opened up the radio to sort this problem, and it seems Tecsun is using some kind of low grade soldering tin that looks (and acts) more like powder.
I needed to resolder most of the board because most of the solders were bad.
I suspect that those Tecsun radios now working good, are prone to fail due to this soldering issue.
All the best,
Moshe.
From my extensive reading and participation in the Yahoo groups, I do not believe many people rely solely on the whip antenna for these radios, even on the road. At home, most people seem to either connect an external antenna or at least a long wire. On the road, many use the roll up antenna provided by the manufacturer. Testing as you are is unrealistically slanting the test results very hard against the Sangean ATS-909X.
Sangean seems to know their target markets very well, and I think it was a conscious decision on their part to optimize FM performance on the whip antenna at the expense of SW performance. They obviously believed that this radio would be used with some sort of additional SW antenna, whether external or adding the reel antenna to the whip, else why would they have included the variable RF Gain control? I have also found the internal speaker on the ATS-909X to be just as good, if not better than the Tecsun PL-880 in FM mode. This is most likely due to the upgraded speaker Sangean used in the 909X (definitely not the same as the ATS-909).
A more realistic test would include a test segment utilizing either an external antenna, or at least the reel antenna provided by the manufacturer.
You also do not do a comparative test for MW DXing. Many of us hams got started at an early age with a simple AM radio and got a lot of enjoyment out of picking up distant AM broadcasters. I have all 4 of these radios, and it is no contest; the Sangean ATS-909X is by far a better MW DXing radio that the others. This is most probably due to the fact that the internal ferrite rod antenna runs the entire length of the case, and the 909X has a large case.
In summation, you picked the only weakness the Sangean ATS-909X has, sensitivity on SW on the whip antenna, as your sole criteria for a travel radio. I think most of us would also expect decent FM and MW performance in addition to the SW. And, as I explained above, most of us on the road would also augment the whip antenna with a reel antenna or some sort of long wire.
If you retested the radios and included FM, AM DXing, and an augmented whip antenna on shortwave, your test results would be a lot different, and the Sangean ATS-909X would win in every category.
Hi, John,
Frankly, I’m mostly concerned with shortwave radio reception on this blog as it’s my favorite band. (In other words, I am biased!) 🙂 I do love listening to MW and FM from time to time, but shortwave is my staple.
This is the longest review I’ve written to date. I agree that it would be great to do one with the same external antenna on each radio–indeed, I might just do this in the coming months–but I simply didn’t want to fit more into this review. It is what it is for the moment.
The ATS-909X is a good radio when hooked up to an external antenna. Indeed, I made a statement in the review to this point:
Thanks for your comment!
Thomas
Cheers,
Thomas
Hi Thomas,
And thank you for the response. I can appreciate your focus on SW, but I will add when traveling I also like to have good AM and FM available for those occasions when you are looking for local weather reports, or just want to relax with some music. I have sometimes also used the radio when out of town to do some AM DXing to pick up Chicago stations to get Chicago local news updates.
I can appreciate also not wanting to evaulate performance on external antennas, but most of these radios come with a reel type antenna as the manufacturers realize that most people want more performance than the whip antenna alone can add, and tend to pack the reel antenna or a small active loop to supplement the whip. And, as I said, it is very common to use external antennas with these radios as Tom Stiles is doing here with the 909X:
http://www.youtube.com/watch?v=pULy1QmSWiA&index=3&list=UULVm5STfCi4fYim73JIKClA
What I think would be useful is to benchmark performance on the whip, and then connect the manufacturer supplied reel antenna to note the improvement, if any, in reception. Some radios, such as the 909X, tend to come alive with a few more feet of wire added.
It would also be useful in a travel radio to be able to operate the radio while charging the batteries. the 909X is excellent in this regard; the Tecsun PL-880 is a disaster when using any kind of charging source other than a laptop USB port, and even then the audio suffers from artifacts. Given the bad press Li-on batteries have been getting, I am none to sure I would like to travel with spare Li-on batteries for the Tecsun PL-880 simply because I could not use the radio while it was recharging.
Just my thoughts. I did enjoy the review, even though my conclusions were different from yours, and look forward to more.
John
Very good review, an enjoyable reading. I am about to buy a Tecsun PL-660, this review helped me a lot to decide! Keep up the good work Thomas!
Well done Thomas, Always enjoyable to read well written reviews on shortwave radios. As a member of the Australian Radio DX Club, radios capable of good shortwave reception and medium wave reception are of great interest to me
Of the radios reviewed, I own 3 of the 4 although I’ve had the opportunity to listen on the Sony. I concur wholeheartedly with your findings. I do enjoy the PL880 most of all despite it’s obvious quirks. I have however bought a radio that does outperform all on SSB and with a Synchronous detector that is the best I’ve come across in portable radios, dare I say it? The Grundig G3! I have to say my sample is superb in this area. The SSB is spot on, better than my PL880 which I have to add is excellent and its Synchronous Detector holds lock even during the heaviest of fading, very impressive. Somewhat surprising considering a lot of negative press about the G#, especially earlier examples. David’s mention of the CR-1 is worthy as well, I’m very impressed with my CR-1, I will be taking it on DX’pedition to Darwin in Northern Australia shortly and will be looking forward to testing its capabilities.
Another radio worthy of consideration is the Tecsun PL390, a surprising performer however not capable of SSB reception. Keep up the great work Thomas, look forward to the next installment!
…Sony should remake the Sony icf 7600 gr with a tuning knob, DSP chip, VHF air band , make it more fuel (battery efficient)….and then maybe it would be the cat’s ass of radios!
Why not and any feedback?
Sony is far too busy right now trying to survive to worry about a niche as small as shortwave. I’m pretty sure the 7600gr is the last serious shortwave radio we’ll see from them.
Sony did all that before… With the ICF-2010.
Great review. After years of holding off, I think I may grab a 7600 before they’re gone.
no maybes about it sir Sony would wipe the floor with them 73s sir great comment.
I prefer the 7600GR tuning arrangement when listening at night in bed. I find it easier to tune by pressing a button rather than turning a knob.
A knob can be very useful, but I’m satisfied with the Sony’s arrangement. One set of buttons mutes the radio and the other doesn’t. I replaced the IF filters with better ones, the 455kHz filter was too asymmetrical for me. The original AM filter appears to be a Murata CFWLB455KJFA-B0, I replaced it with a better one. I also replaced the FM filters with Murata 150kHz units; the improvement was impressive. Tuning knobs worry me at these prices. We can’t expect the best rotary encoders in radios at lower prices. These encoders often start misbehaving after a while, since they’re not units of the highest quality as were used in “kilo dollar” receivers.
Excellent review!
As far as digitally tuned mid-priced portables are concerned, I personally own the Tecsun PL-660 as well as its “older brother” the PL-600. Both are excellent receivers; I think China for once has done a very good job, at least in the SWL field.
Because of its higher sensitivity, excellent sync detector performance, lower noise floor and the possibility to separately choose in between LSB and USB modes, the PL-660 is almost always my first choice whenever I’m out home and want to DX pirate radio signals, SSB signals (such as ham stations in the amateur bands or utilities such as oceanic ATC), or weak broadcast signals (like the exotic Voice of Korea as received from inside the city of Barcelona).
But when I feel like listening to strong and clear sounding SW broadcast stations (specially if there’s music aired, like in Radio Kuwait each local evening in 15540 KHz starting at 1930UT, or in the 10 KHz wide CRI Spanish broadcasts for example), or even to music stations in the local FM band, I always tend to reach for the PL-600. It has a slightly warmer audio than the PL-660. The PL-660’s audio tends to have a bit more presence in the high audio frequency region, and sacrifices a bit of the sonority in the low audio frequencies; this results in a slightly sharper sounding sound which is good for improving the intelligibility in voice signals, but which is not as pleasant for music like the audio out of the PL-600 that balances the highs and lows very well.
Because I made a recommended PL-600 mod in mine, to eliminate annoying audio distortions when listening to strong SSB signals (by soldering a resistor in between pin 18 -AM IN- of the TA2057N main IC and ground) I find it handles strong signals better than the PL-660 (at the cost of lowering the intensity of the audio in AM and SSB -not when selecting the FM broadcast band- at the maximum volume setting). The AGC also seems to be more stable in my PL-600, as it seems to perform better than the PL-660’s in attenuating fading when strong broadcasting signals collide with poor propagation conditions – perhaps this is due to the modification “unloading” the circuit and making it work with less “weight in its shoulders”. Also, my PL-660 sometimes exhibits a “soft muting”-like effect when fading is very pronounced. I think this may be a product of a “bad batch” of receivers coming out of the factory, as it has two other defects as well – not very annoying after I got used to them (one of them being the center setting in the SSB BFO knob not being the same than its physical center position – the “notch” or “detent”). So my PL-600’s AGC seems to be the best performer.
Another positive point in favour of the PL-600 is the ergonomy. I feel that the buttons and keys in the front panel have a softer press on them than in the PL-660; they’re also bigger. So, to me, the PL-600 is more pleasant to operate.
Finally, and although I’ve not mentioned it until now, I’ll say that I own the CommRadio CR-1 as well; a receiver that I feel should not be considered only as a desktop receiver, but as a portable one as well, its (overpriced) price tag permitting. Because it sports SDR technology I think it does not compare directly to “HDR” (Hardware Defined Radios) such as the PL-600 and PL-660. But I always tend to choose it over the Tecsuns when I want to listen to SSB and/or weak signals (and I am in a suitable and stable location -be it at home or outdoors- for setting up the CR-1 and also at least a short antenna wire) because of its very good SSB and distortion-less strong signal performance and because it offers functionalities that were only seen before in desktop receivers. For example: 10Hz frequency readout resolution in the display, standard S-units displayed in the S-meter -rather than the unknown 1-to-5 scaling in the Tecsuns’ “signal intensity meter”-, an even lower noise floor -thus better sensitivity- than in the PL-660, no sync but very good ECSS performance, and several filter bandwidth and AGC speed choices, to name a few. Also, I feel the front tuning knob very delightful to use and closer to the feeling of the few weighted big knobs of big desktop receivers and transceivers that I’ve been able to turn! The flimsy and prone to fail encoder that is driven by this knob “downrates” it a bit, but when everything works correctly -like right now- the CR-1 is highly enjoyable to tune.
Not a receiver for music, though: even at the widest filter setting AM audio sounds tinny, without any trace of basses and really sharp – not only out of the internal speaker, but also out of any external speaker and headphone that is plugged in to the CR-1. The receiver has an advantage in being an SDR, though: with a firmware update containing improved software demodulators and different widths for the software-defined filters, all these problems should be gone with independence of the hardware that runs this firmware and the CR-1 should sound marvelously in AM (I only hope CommRadio to release another update soon, as the next one was scheduled for May and nothing happened then or later…). Some work should be done in improving the AGC performance as well, as strong static crushes momentarily and completely deafen the receiver – something that is partially (but, unfortunately, not completely) solved by setting the AGC speed to “Fast”.
A Mega Comment for a Mega Review 🙂
73 from Spain! (main QTH in Barcelona – now in an almost QRM-less location in the northeastern Spanish countryside near the very small town of Arén!)
David – EA4998URE SWL
Personally, after having played around with each, I agree that the Sangean is very disappointing when using the internal antenna. That, to me, is very unfortunate because it has the potential to be a wonderful rig.
However, I have an entirely different take on the Sony. Perhaps this is because I tend to dx the AM and FM broadcast bands first, before tinkering with SW. The Sony has dreadful reception on FM. It’s not particularly sensitive and (even worse) not particularly selective. Out of every comparable radio I have, the Sony has the worst FM receiver. Almost useless for out of market FM signals. Now, as far as AM goes, it is very good to excellent and on par with the PL-660 and PL-880, if not a little better. It’s LW is better still. And, it’s SW section is excellent and it’s SSB and sync detector are the best in class. That said, tuning with the old fashioned “up and down” buttons is a user-unfriendly chore. Because of this, I find that I use the Sony far less than the others.
The Tecsuns aren’t perfect, but they do cover every band well. The PL-880 has better selectivity while the PL-660 is a tad more sensitive (on all bands). It comes out as “a wash” as to which is “better”. Although I usually listen with headphones, the sound from the PL-880’s speaker is SO good that it encourages me to unplug sometimes just to listen to the warm, room-filling sound.
Overall, I suppose which one to choose is a matter of personal taste – just as Thomas so wisely stated. In closing, this was an excellent review and I really enjoyed reading it…nice work!
It’s tough job trying to find common ground for testing “similar” devices. You’ve done very well.
As someone noted: a tad embarrassing for Sangean. The venerable 909 was excellent value-for-money for years. Mine has a cracked display, pieces out of the case, no battery cover, the labels worn off and the dregs of the WRTH “best receiver 1996” label. The speaker packed it in years back (foam decay), but it’s still used today with headphones. I love it.
The 909 is deaf by itself – that was an advantage in my work ironically – but its front end is the toughest I’ve found in a consumer-grade portable. Any experienced hf user knows “sensitivity” is the least important receiver criterion cf. selectivity, stability, image rejection & sound. With an 8 metre bit of wire for an hf aerial the 909 was as sensitive as any other portable. With a “real” aerial it’s a communication receiver in disguise. VK amateurs love the 909 as a back-up rx. There’s a utube of one hooked into a 4×4 tci array & tuning the aero band around 11MHz – about 18 dBd of aerial gain next to the 25m band & the receiver was unconditionally stable. The 3-way aerial socket (not documented inthe manual) was a boon for mf listeners who could plug in a tuned, shielded loop aerial & bypass the the internal ferrite rod.
Having said all that I might have to get a PL-880, maybe after the firmware has settled down. Unless Sangean produces a “909Z” with DRM/DAB+ capability in which case all bets are off. Is that a Wessex saddlback I see doing aerobatics…
Nigel Hi,
I was abel to get my 909 hot with it’s telescopic antenna (improved contact to the antenna, and isolate it from shorting with the speaker’s (-) terminal). now it receives very well on all bands with only it’s telescopic antenna.
the price: noise level on FM increased and auto scan is no longer possible.
As you mentioned, connecting the Sangean to external antenna, and you get A communications receiver.
All the best,
Moshe
I’d like to see a grid type chart of these radio’s features and specs. The 880’s tuning step and filters are extremely interesting and perhaps someone like Craig Siegenthaler of Kiwa fame might be called upon to measure filter skirts and overall effectiveness.
Exceptionally well done review! Well balanced and a pleasure to read, Thank you Thomas!
I own the Sony SW-7600GR & the Tecsun PL-660. I carry the Sony with me on trips. I like that the Sony has a slide switch to lock it off when traveling. Lack of a tuning knob is no big deal to me. With headphones, the Sony’s audio sounds great. Mostly I like the Sony’s solid construction. I will purchase the Tecsun PL-880 & also another Sony as a spare. Not sure how much longer Sony will offer their SW-7600GR. Thanks for your fine review – much appreciated.
Tony
How much use has your 7600gr had? I have one and am wondering how long I should expect it to last if taken well care of??
Thank you for this very informative review and audio clips. This has really helped in finalizing my decision for a portable SW/ham band receiver.
Before this article I was trying to decide between the ATS-909X and the PL-880. I’m going with the 880 because the audio especially on SSB and weak DX to my ears is sharper and clearer thus producing better audio “intelligibility”.
My mid range hearing is not what it once was and glad that some manufactures are working on improving the audio. Would be nice to see a software driven RX EQ feature in the next portable receivers.
Great review! Thanks for doing it. The only one of these I have is the Sony, and my feelings about it are the same as yours.
Is the PL 660 the same as the Eton E-10 that was around in the mid 2000’s? I have that one and it looks identical, but if the PL 660 is an upgrade or a completely different radio, I might go for it.
Thanks again.
@ Ken K. in NJ: I think you’ll find documentation that the PL-660 recycles the E-10’s case molding but is basically completely different internally. (More closely related to the PL-600 than the earlier Eton.)
We likely now have the definitive review of current portable shortwave radios 🙂 .
I just got back from a week of camping and had along my Tecsun PL-600 (not tested I know) for afterdark headphone listening. A few notes: First, the plastic volume knob had previously slipped off my PL-600 and was lost, so I borrowed the BFO knob (which also came off easily) as I was not doing any SSB. The point, the Tecsun feels a bit cheap and not durable for the long haul. Secondly, I pretty much know what frequencies I want to tune and almost always used the PL-600 number keys for frequencies: 11780, 6000, 6925, 12070, 13650 etc., rarely used the tuning knob. Third, camping after dark I listen on headphones so speaker quality is a secondary for me.
Therefore, my choice for a portable would have to be the Sony ICF-SW7600GR as it seems built to last, with solid performance and features and the key pad tuning may not be a problem for the SWL who has ‘go-to’ frequencies.
Would love to see Sony update the 7600 once again to show the new kids how it’s done.
All Tecsun radios are cheap, with truly appalling build quality, they’re cabinets and knobs being fabricated from thin, very brittle plastics! One can easily envision them shattering in dozens of shards with nothing more then a good bump, let alone a fall from waist height to the floor! I ordered both the PL-660 and the PL-880 from Universal Radio and was simply appalled by the cheapness of their construction, and immediately returned both, both being grossly overpriced, with the PL-880’s $160.00 tag being laughable at best! Simply stated I have a hard time taking seriously, anyone who renders a favorable opinion of either because of it!
Re: Chris Sarno’s comments above: It is OK to criticize the radio but to criticize people who have a different opinion of the radio than yours is a bit over the top. Get some help and save your future comments for your therapist.
Attacking each other for any reason goes against everything amateur radio stands, (i.e. in accordance with good conformity and good engineering). I realize not everyone has an FCC license to transmit on SSB, USB, LSB, CW etc, but we all can use a receiver and tune to these bands. I hope everyone will treat each other with kindness, as a fellow hobbiest and allow their good natures to outshine the negativity.
Kind Regards,
K4BOX
Poprawno?? polityczna?
I don’t know about your comments, they differ from my experience. I’ve had 2 PL-660’s since 2011 and They both have held up well. I have broken the whip antenna, but that was more due to my own bumbling than the build quality.
I do agree that they are a little on the cheaper side but they are priced accordingly and mine are still going strong and have served me well for over 5 years now.
SIR WHICH ONE RADIO IS BEST FOR SW
That review is a masterpice!
well, very embaressing for the Sangean, as I own the 909, and the 909X was suppose to be an improvement over it…
I have ordered the Tecsun S2000 from Anon-co, I am sure this rig will be much better on LW, MW, and Shortwave of course.
The sony, again proves to be a REAL radio, and beside it’s ergonomics, It looks a very joyfull radio to use.
Both Tecsun’s would be my choice, as a tunning knob is a must for me (and the Tecsun S2000 definitly has one!)
Well done Thomas! I couldn’t stop reading.
All the best.
Moshe.
Well done Thomas, two years ago I made a decision on which of the three, 880 not available at the time, to buy. I ended up with the 660 and really glad I did. After your sample testing’s, The 880 sounded excellent, I might just go out and buy one now, wouldn’t mind tinkering with it’s hidden features.
I had a 660 but I gave it as a gift to my brother.
I have now ordered a 880.