 Many thanks to SWLing Post contributor, Bill Hemphill, who shares the following guest post:
Many thanks to SWLing Post contributor, Bill Hemphill, who shares the following guest post:
Simple Android Database-PART 2
by Billy Hemphill, WD9EQD
In the first part, I showed how you could easily take a spreadsheet and create a simple database for viewing on an Android phone/tablet. The examples used in that article was two spreadsheets of radio schedules – one for Shortwave and one for FM Radio Programs. See the following link to the original article: https://swling.com/blog/2021/10/guest-post-radio-schedules-in-a-simple-android-database/
There are many lists on the internet of various radio databases. If the database can be downloaded as either a CVS file or a spreadsheet, then it is possible to load it into the PortoDB app on the phone tablet. I’ll show how this can be done with two popular databases that I reference all the time.
EIBI Data Base
Most of you are probably familiar with the EIBI database of shortwave schedules. Many of the Shortwave Schedule apps on the Phones reference this database. For example, I use the Skywave Schedules on my phone. While it does allow for me to search by many parameters, I thought it might be fun to have it in a PortoDB database. Plus it would be interesting to see how PortoDB performs with a large data set.
Fortunately, the EIBI is available as a CVS file. Just go to the following and download it:
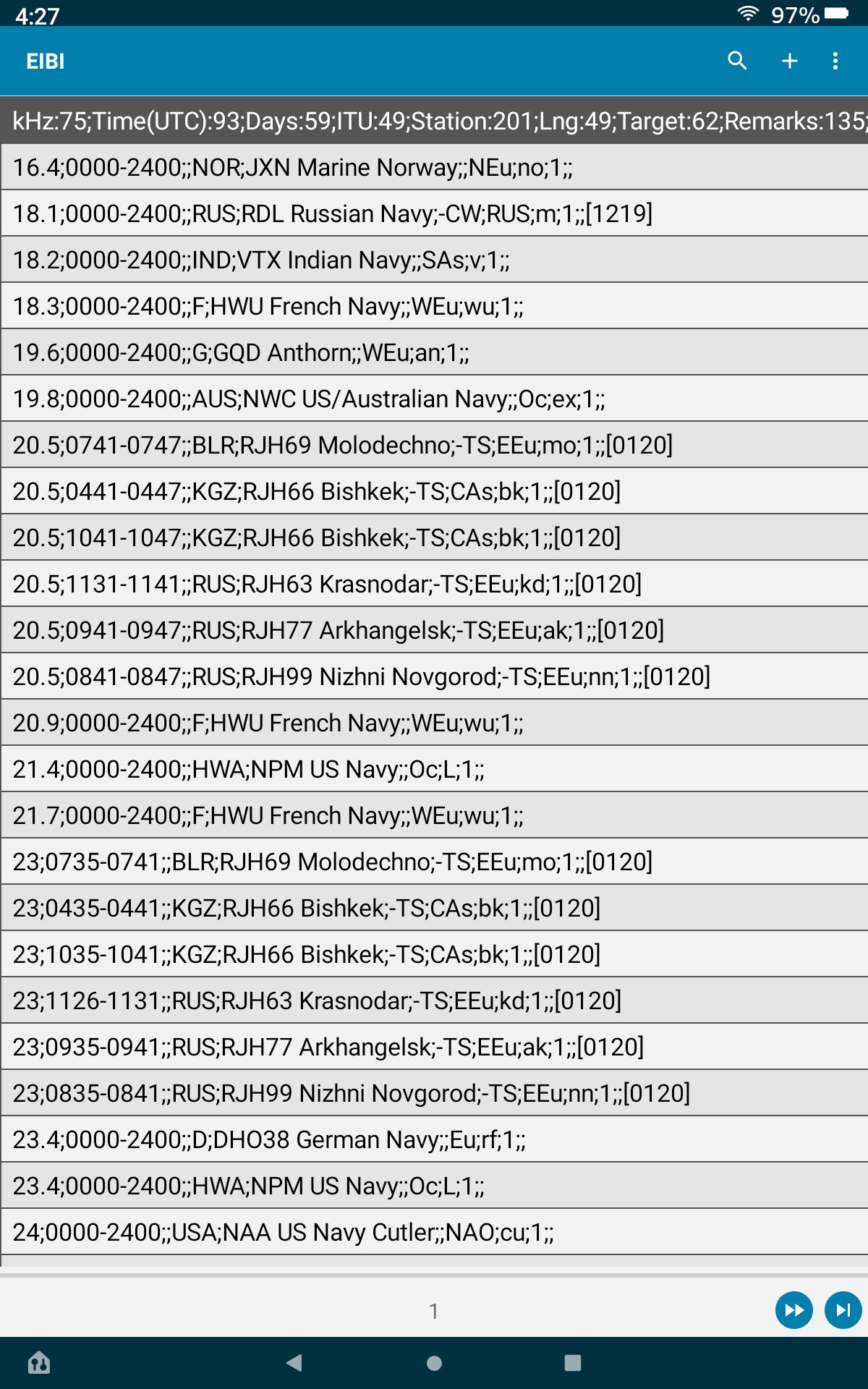
The CVS EIBI file uses semi-colons as the delimiter between fields. The first line is the header for the various columns. For example, first few lines of CVS text file:
kHz:75;Time(UTC):93;Days:59;ITU:49;Station:201;Lng:49;Target:62;Remarks:135;P:35;Start:60;Stop:60;
16.4;0000-2400;;NOR;JXN Marine Norway;;NEu;no;1;;
18.1;0000-2400;;RUS;RDL Russian Navy;-CW;RUS;m;1;;[1219]
18.2;0000-2400;;IND;VTX Indian Navy;;SAs;v;1;;
18.3;0000-2400;;F;HWU French Navy;;WEu;wu;1;;
19.6;0000-2400;;G;GQD Anthorn;;WEu;an;1;;
19.8;0000-2400;;AUS;NWC US/Australian Navy;;Oc;ex;1;;
The first thought is to just send this CVS file to the phone/tablet and Import it into a table. This will create a table with 16,995 rows. But if you do that, then you will get the following:
PortoDB uses Commas as delimiters, not semicolon. You need to change the semicolons to commas in the original file before you import it into the table. Any text editor can be used to do a global replace of all semicolons with commas. Once that is done, it can be imported into a table:
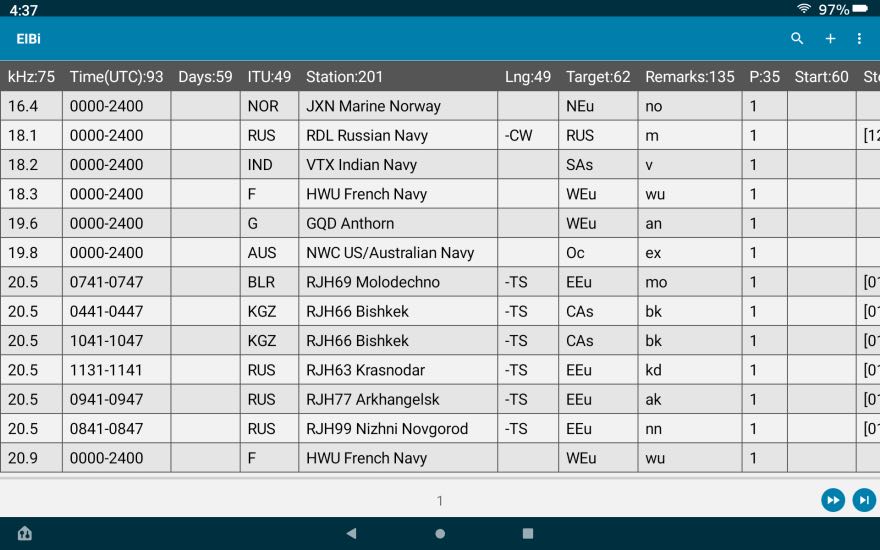
Beautiful; now the data has all the columns. You need to scroll to the right to see all the columns.
After reviewing the data, I realized that I don’t need all the columns and probably don’t need all the rows of data. I recommend downloading the Readme.txt file from the EIBI website. This file describes the layout of CVS file. There are 11 columns (or as the readme file calls it – “Entry”). They are:
Col 1: Frequency in kHz
Col 2: UTC Start and End Time
Col 3: Days of Operation
Col 4: ITU Code
Col 5: Station Name
Col 6: Language Code
Col 7: Target Area Code
Col 8: Transmitter Site Code
Col 9: Persistence Code
Col 10: Start Date
Col 11: End Date
After playing around with the data, I found that I wanted the data arranged as follow:
Col 1: Frequency between 4000 and 24000 kHz
Col 2: Start Time
Col 3: End Time
Col 4: Days of Operation
Col 5: Station Name
Col 6: Language
Col 7: Target Area
I wrote an AWK program, EIBI.AWK, that will take the original EIBI.cvs file and create a new file in the format I wanted. This program will change the semicolons to colons, filter the frequency to 4000-24000, split the time into Start and End times, and filter the Language column to English only. This AWK program can easily be change to filter in other ways. It also adds a space before frequencies less than 5 digits. This is so that portoDB can sort correctly. And Quotes are added around the Days of Operation and Station Names to ensure that commas in these field get handled correctly.
Program EIBI.AWK:
# EIBI.AWK
#
# print the first line with the column headers
BEGIN {print "kHz,Start (UTC),End (UTC),Days,Station,Language,Target"}
{FS=";" # set the input file separator
OFS="," # set the output file separator
q="\"" # set q to quote symbol
# set k = to the khz. add a space in front if less than 5 digits
if (($1+0) > 9999)
k=$1
else
k=" " $1}
# split the time into start and end times
{split($2,t,/-/)}
#cycle thru the file starting at row 2 (ignore row 1 headers)
#only include freq from 4000 to 24000 and english
{if ((NR ! 1) &&
(($1+0) > 4000) &&
(($1+0) < 24000) &&
($6 = "E"))
print k,t[1],t[2],q$3q,q$5q,$6,$7}
The resulting output file looks like this:
kHz,Start (UTC),End (UTC),Days,Station,Language,Target
4005.5,0000,2400,””,”Dutch Military ALE”,E,HOL
4005,0000,2400,””,”NSS US Navy RTTY/STANAG”,E,NAm
4010,0000,1800,””,”Birinchi Radio”,E,CAs
4010,0105,0110,”Sa”,”Birinchi Radio”,E,CAs
4010,0140,0150,”Sa”,”Birinchi Radio”,E,CAs
4010,0155,0200,”SaSu”,”Birinchi Radio”,E,CAs
4010,0325,0330,”Mo-Fr”,”Birinchi Radio”,E,CAs
4010,0445,0454,”Mo,We”,”Birinchi Radio”,E,CAs
4010,0500,0505,”Mo-Fr”,”Birinchi Radio”,E,CAs
4010,0505,0530,”Mo-We”,”Birinchi Radio”,E,CAs
4010,0535,0600,”Mo,We”,”Birinchi Radio”,E,CAs
4010,0605,0620,”Th,Fr”,”Birinchi Radio”,E,CAs
4010,0620,0623,”Mo-Fr”,”Birinchi Radio”,E,CAs
4010,0623,0640,”Th,Fr”,”Birinchi Radio”,E,CAs
4010,0645,0700,”We-Fr”,”Birinchi Radio”,E,CAs
4010,0705,0710,”SaSu”,”Birinchi Radio”,E,CAs
This file can now be imported into PortoDB with following results: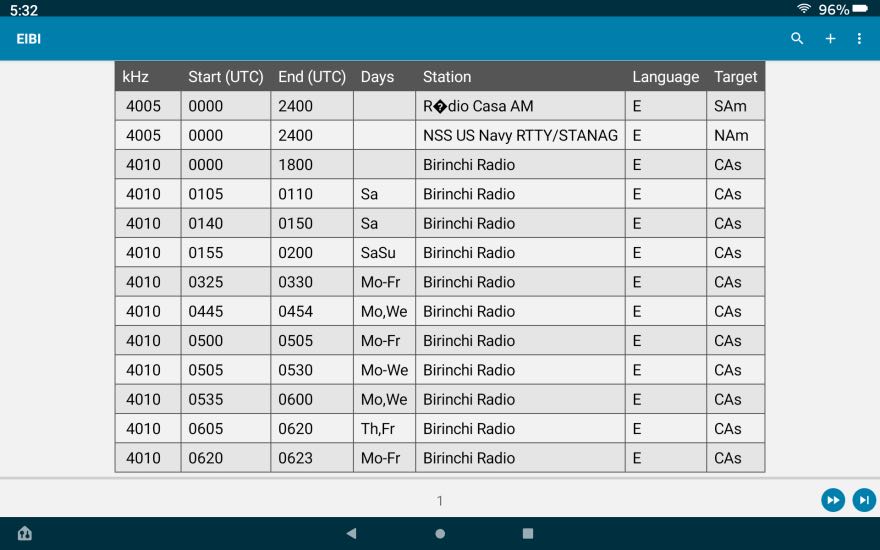
I can now sort by Station, Start time, Target Area, etc.
While this data is in the App Skywave Schedules, I find that for many purposes, sorting and searching the EIBI database directly works better.
Mesa Mike’s List of USA AM Band Radio Stations
I am always using my loop antennas to see what AM radio stations I can hear. While there are many websites to help with determining what station is on what frequency, I have found that Mesa’s Mikes List of USA AM Band Radio Stations to be a good first place to look:
http://mesamike.org/radio/cdbs/amdb.mvc
His site compiles the list daily from FCC data base. You can scroll through the listings or search by Frequency and/or State.
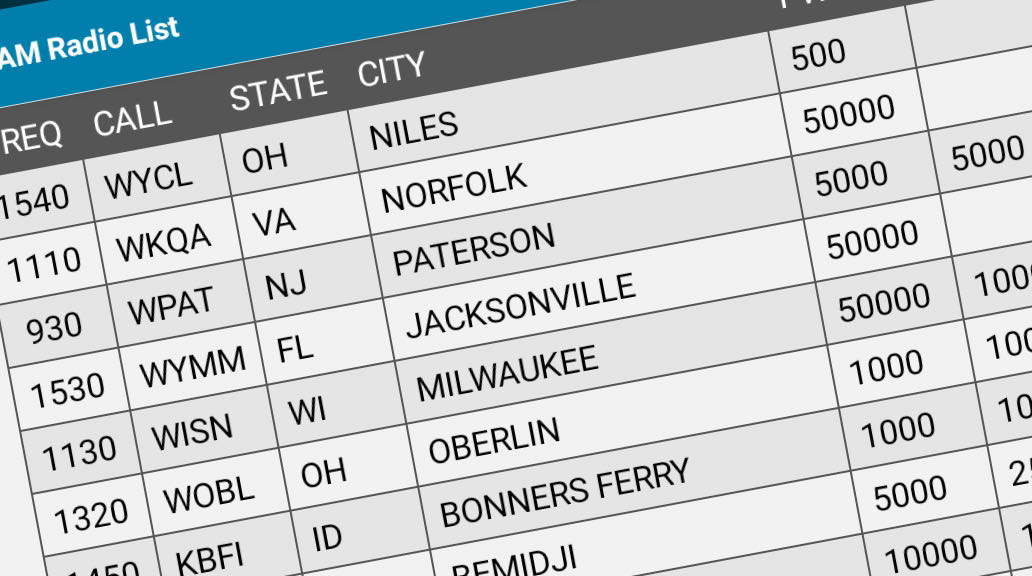
But the best part is that you can download the current list as a delimiter text file. The CVS file uses the Vertical Bar character as the delimiter. This needs to be changed to a comma for importing into a table in PortoDB. Following is first few lines of the downloaded file;
Last Updated Mon, Jan 04, 2021 at 1002 UTC
APP_ID|FAC_ID|FREQ|CALL|STATE|CITY|PWRD|PWRN|PWRC|LAT|LON|STATUS|
APP_ID|FAC_ID|FREQ|CALL|STATE|COL|PWR_D|PWR_N|PWR_C|LAT|LON|NOTE
153|73308|1540|WYCL|OH|NILES|500|||41.1322|-80.7611|
598|29597|1110|WKQA|VA|NORFOLK|50000|||36.9428|-76.5322|
604|51661|0930|WPAT|NJ|PATERSON|5000|5000||40.8497|-74.1831|
608|11127|1530|WYMM|FL|JACKSONVILLE|50000|||30.3639|-81.7483|
619|65695|1130|WISN|WI|MILWAUKEE|50000|10000||42.7550|-88.0814|
623|73364|1320|WOBL|OH|OBERLIN|1000|1000||41.2681|-82.2111|
634|54500|1450|KBFI|ID|BONNERS FERRY|1000|1000||48.6889|-116.3344|
635|9665|1360|KKBJ|MN|BEMIDJI|5000|2500||47.4422|-94.8658|
639|9412|1030|WOSO|PR|SAN JUAN|10000|10000||18.3686|-66.2547|
643|47079|1260|WXCE|WI|AMERY|5000|5000||45.2569|-92.3667|
652|67672|0910|WJCW|TN|JOHNSON CITY|5000|1000||36.4103|-82.4536|
656|54873|1340|WVCV|VA|ORANGE|1000|1000||38.2539|-78.1208|
I wrote another AWK program to take the downloaded file and put it in a better format for importing into a table. Following is the AWK program
AM.AWK:
#! /usr/bin/awk -f
# print the first line with the column headers
BEGIN {print "FREQ,CALL,STATE,CITY,PWR_D,PWR_N"}
{FS="|" # set the input file separator
OFS="," # set the output file separator
q="\"" # set q to quote symbol
# set k = to the khz. add a space in front if less than 1000
f = $3 + 0
if (f > 999)
k=f
else
k=" " f}
#cycle thru the file starting at row 4 (ignore the 3 headers)
{if (NR > 3)
print k,q$4q,q$5q,q$6q,$7,$8}
The AWK program selects only certain columns, skips the header lines, write a new header line and adds a space before any frequency that is less than 1000. It also adds Quotes around some of fields to ensure that they get imported as text fields.
The resulting output file after processing by the AWK program is;
FREQ,CALL,STATE,CITY,PWR_D,PWR_N
1540,”WYCL”,”OH”,”NILES”,500,
1110,”WKQA”,”VA”,”NORFOLK”,50000,
930,”WPAT”,”NJ”,”PATERSON”,5000,5000
1530,”WYMM”,”FL”,”JACKSONVILLE”,50000,
1130,”WISN”,”WI”,”MILWAUKEE”,50000,10000
1320,”WOBL”,”OH”,”OBERLIN”,1000,1000
1450,”KBFI”,”ID”,”BONNERS FERRY”,1000,1000
1360,”KKBJ”,”MN”,”BEMIDJI”,5000,2500
1030,”WOSO”,”PR”,”SAN JUAN”,10000,10000
1260,”WXCE”,”WI”,”AMERY”,5000,5000
910,”WJCW”,”TN”,”JOHNSON CITY”,5000,1000
1340,”WVCV”,”VA”,”ORANGE”,1000,1000
540,”KWMT”,”IA”,”FORT DODGE”,5000,170
This file can now be directly imported into a Table in the PortoDB. The results are:
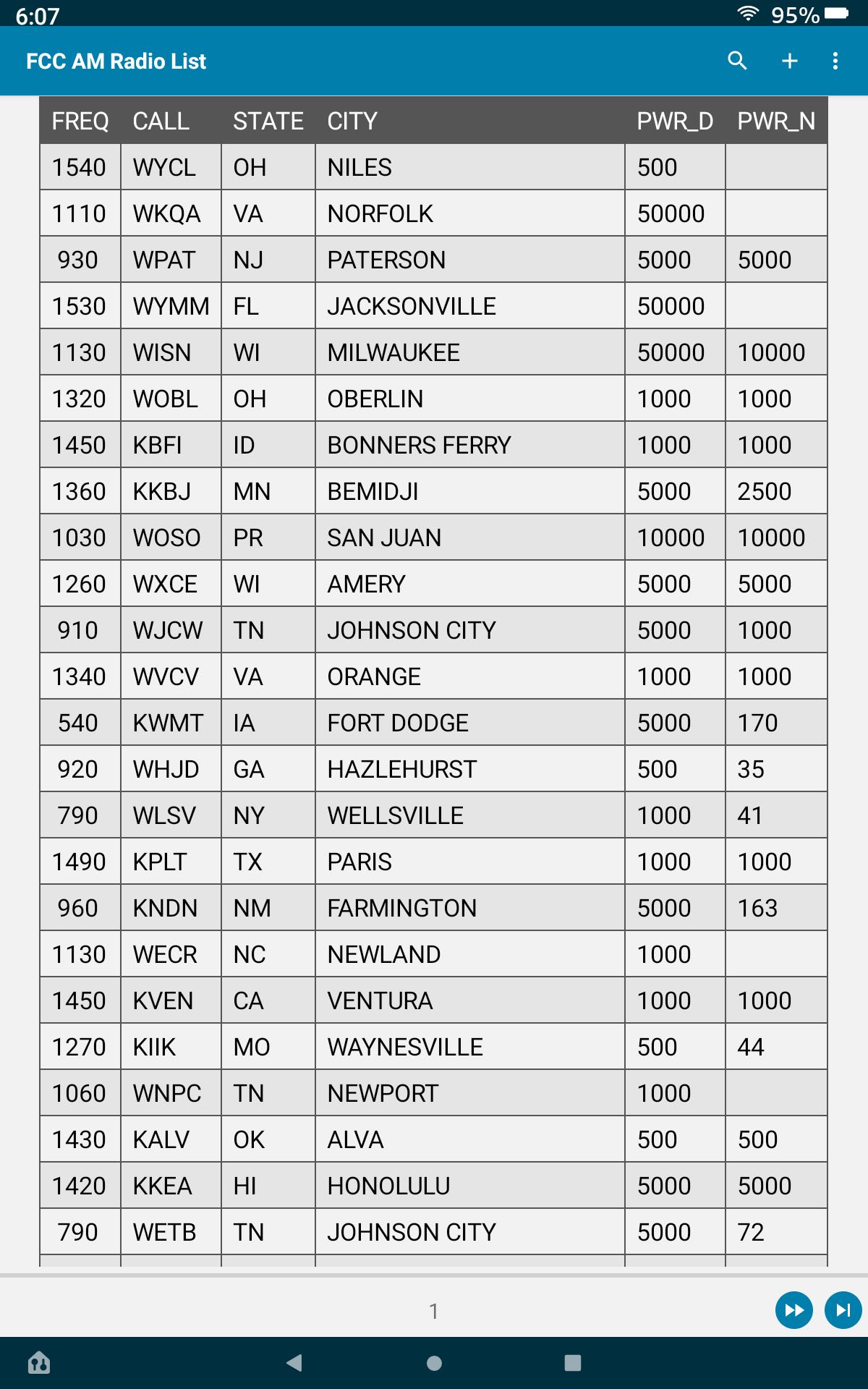
You can now sort by any column or combination and search on any particular value to create a subset of the data.
In conclusion, any set of data that can be presented in a CVS format can easily be imported into a table on your phone/tablet for ready reference at any time.
If anyone knows of any other useful datasets, please let us know.
Final comment about the AWK program
I’m sure many of us (especially Linux users) are already familiar with how to use it. It’s a great utility program for quickly manipulating text files in many different ways. While it is a standard utility on a Linux computer, it can also be used on a Windows system. Gawk for Windows can be downloaded from:
http://gnuwin32.sourceforge.net/packages/gawk.htm
Once installed, AWK can be run on a Command Line in a Command Window. To keep it simple, I created Batch files:
REM EIBI.BAT
awk -f eibi.awk < %1 > %2
I then just run the batch file as:
EIBI sked-a21.csv eibi.csv
This takes the downloaded file sked-a21.cvs and processes it into a new file eibi.csv which can then be imported into the database table.
I have a similar batch file for processing the Mesa Mike database.
AWK is very powerful. If you are not familiar with it, I recommend you spend some time review some of the many online tutorials.